統計表の組み合わせ。 統計の解決策の例を持つ講義 - ファイルn1.doc
(資料)
n1.doc。
9.ステートテーブル
統計的要約とグループ化の材料を含みます。統計では、列はグラフと呼ばれ、文字列は文字列です。
テーブル名*
| 弦 | グラフ | 最後のグラフ |
||||
| 1 | 2 | 3 | ||||
| 行名 | ||||||
* - 注意
タイトルなしのテーブル - スケルトンタイトルのみ - レイアウト.
デジタル材料は、絶対的な、相対的および媒体であり得る。
テーブルの対象の構造に応じて、シンプルで複雑なものがあります。 シンプルなテーブル モノグラフィとラグがあります。 モノグラフィックテーブルは全体の全体的なものではなく、1つのグループだけです。
テーブルのリスト
シンプルテーブルの対象は、次の原則によって形成されます。
普通
領土。
一時的。
組み合わせテーブル - 1つのもののいずれかの兆候に影響を与えるが、多くの要因を示しています。 各グループはサブグループに分割されています。
タグの性質に応じて 統計表にあります シンプルで複雑な開発。 ために 忌plain フェードされたインジケータの開発はサブグループに分けられます。 繁雑 開発には、サブグループのサインの区分が規則として、「含む」レコードが含まれています。
基本的なルール テーブルのコンパイル:
タイトルは短くて理解できます。
別々に、最後の列には「含む」レコードを作ることができます。
必要に応じて - 番号付き。
legend:現象がない場合は、「...」、「情報なし」、「X」がない場合は「いいえ情報」がない場合は、「 - 」があります。 数が撮影された精度より小さい場合、0.0が書き込まれます。
同じ程度の精度。
テーブル内で何かが計算されると、この値が計算されることを示しています。
意味のある分析 - テーブルの内部内容の研究。
論理分析 - 不条理の程度をチェックする。
会計解析 - 個々の値の選択的計算
CONAMS表は、2つ以上の属性機能の共通のセットの要約数値特性、または属性と定量的サインの組み合わせを含む表です。 社会現象の研究に使用されています。 最も単純な形式のマトリックス(この場合は共命テーブル) - 2x2。
| B1。 | B2。 | 合計 |
|
| A1 | A11 | A12。 | A10 |
| A2。 | A21。 | A22。 | A20。 |
| 合計 | A01。 | A02。 | A00。 |
内部デジタル充填テーブルAは同時に周波数です
私。1つの意味 j別の値の両方。
2種類のマトリックスを区別します。
長方形(寸法 m バツ。 n);
平方。
それらに基づく現象およびプロセスの行列および分析は、マトリックスモデリングのデータベースであり、経済的オブジェクト間の関係を調査することを可能にする。
共役テーブルはテーブルと呼ばれ、これは2つ以上の属性(定性的)機能の共通の組み合わせまたは定量的および属性の特徴の組み合わせの要約数値特性を含む。
コナムテーブルが大きいです。
セミナーNo. 1。
| # 工場 | 平均年間費用、百万ルーブル。 | 年間平均労働者、人々。 | 会社の版、百万ルーブル。 |
| 1 | 300 | 360 | 320 |
| 2 | 700 | 380 | 960 |
| 3 | 200 | 220 | 150 |
| 4 | 390 | 460 | 620 |
| 5 | 330 | 395 | 640 |
| 6 | 280 | 280 | 280 |
| 7 | 650 | 580 | 940 |
| 8 | 660 | 200 | 1190 |
| 9 | 200 | 270 | 254 |
| 10 | 470 | 340 | 350 |
| 11 | 270 | 200 | 230 |
| 12 | 330 | 250 | 190 |
| 13 | 300 | 310 | 140 |
| 14 | 310 | 410 | 300 |
| 15 | 310 | 635 | 250 |
| 16 | 350 | 400 | 790 |
| 17 | 310 | 310 | 360 |
| 18 | 560 | 450 | 800 |
| 19 | 350 | 300 | 250 |
| 20 | 400 | 350 | 280 |
| 21 | 100 | 330 | 160 |
| 22 | 790 | 260 | 1290 |
| 23 | 450 | 435 | 560 |
| 24 | 490 | 505 | 440 |
| 合計 | 9500 | 8630 | 11744 |
運動1。 固定資産の費用で工場のグループ化を行います。
1)各グループの植物数とその数を決定します。
2)各グループの固定資産の総コストを決定します。
3)各グループの固定資産の平均値を決定します。
4)植物の総数における各グループの割合を決定します。
5)結論(?)を作ります。
n - 間隔の数
間隔の大きさ
値
秘密の式によって。 仲良くする n = 5 .
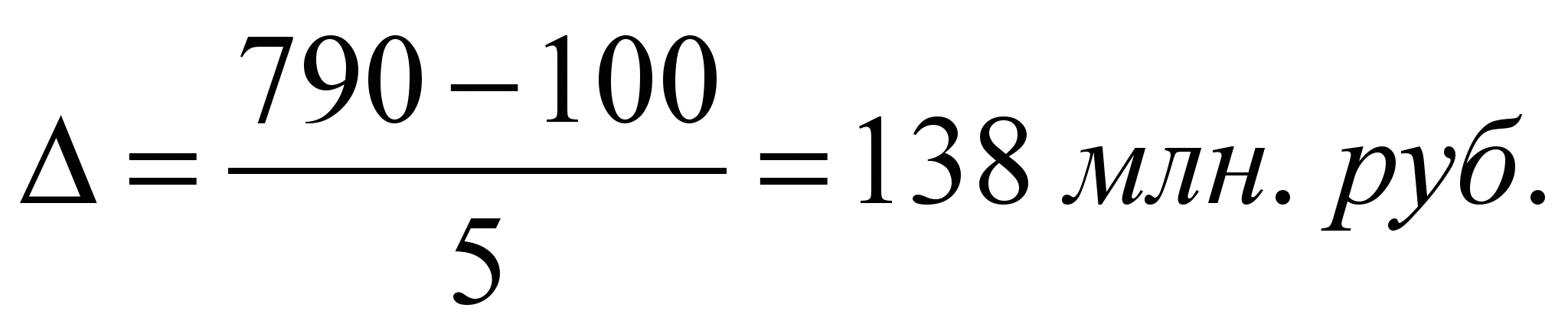
| グループ番号 | 工場グループ | 植物番号 | 工場の総数 | グループでは、の総費用 | グループの平均コスト | 総数(植物数による)のグループのシェア、% |
| 1 | 100-238 | A. | 3 | 500 | 166.67 | 3*100/24=12.5 |
| 2 | 238-376 | b | 11 | 3440 | 312.73 | 45 |
| 3 | 376-514 | C. | 5 | 2200 | 440 | 21 |
| 4 | 514-652 | d | 2 | 1210 | 605 | 8 |
| 5 | 652-790 | e. | 3 | 2150 | 716.66 | 12.5 |
a \u003d 3; 9; 21。
B \u003d 1; 五; 6; 11-17; 19。
C \u003d 4。 十; 20; 23。
E \u003d 2; 8; 22。
タスク2
従業員のグループプラント、 n=5.
5つのグループを服用してください(労働者数の場合)。
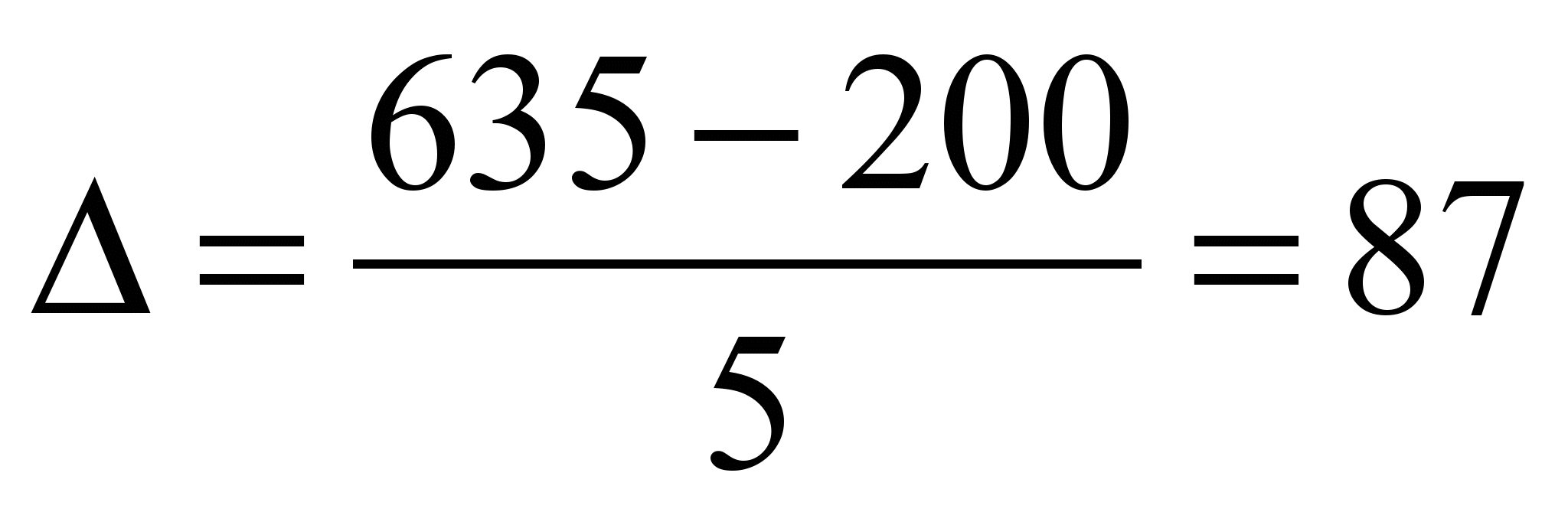 人。
人。
| 群衆 | グループ、人 | ##工場 | 工場数 | スレーブの総数 グループで | スレーブの平均数。 植物で | グループ比重、% |
| 1 | 200-287 | 3, 6, 8, 9, 11, 12, 22 | 7 | 1680 | 240 | 1680*100/8630=19.5 |
| 2 | 287-374 | 1, 10, 13, 17, 19, 20, 21 | 7 | 2300 | 328.6 | 26.7 |
| 3 | 374-461 | 2, 4, 5, 14, 16, 18, 23 | 7 | 2930 | 418.6 | 34 |
| 4 | 461-548 | 24 | 1 | 505 | 505 | 5.9 |
| 5 | 548-635 | 7, 15 | 2 | 1215 | 607.5 | 14.07 |
タスク3 生産量(V)のためのグループ植物、n \u003d 5。

| グループ番号 | 百万ルーブル。 | No.工場 | 工場数 | 全体の体積 | 平均量 | グループ比重、% |
| 1 | 140-370 | 1, 3, 6, 9, 10, 11, 12, 13, 14, 15, 17, 19, 20, 21 | 14 | 3514 | 251 | 29.92 |
| 2 | 370-600 | 22, 24 | 2 | 1000 | 500 | 8.51 |
| 3 | 600-830 | 4, 5, 16, 18 | 4 | 2850 | 712.5 | 24.26 |
| 4 | 830-1060 | 2, 7 | 2 | 1800 | 950 | 18.16 |
| 5 | 1060-1290 | 8, 22 | 2 | 2480 | 1240 | 21.12 |
再配置、二次グループ化
一次群は、統計的観察に基づいて、そして一次グループの二次グループを基にしている。
再グループ化のパス:
間隔を拡大して再グループ化します。
特定の体重のために大幅に再グループ化します。
運動1。
S / N作業2企業のデータ。
| 工場1。 | 植物2。 |
||
| | gr。、% | さまざまなS / Nのグループ化労働者、千万ルーブル。 | 具体的な重量によるGR、% |
| 320-340 | 4 | ||
| 340-360 | 13 | 330-360 | 13 |
| 360-380 | 19 | 360-390 | 31 |
| 380-400 | 25 | 390-420 | 20 |
| 400-420 | 24 | 420-450 | 16 |
| 420-440 | 6 | 450-480 | 17 |
| 440-460 | 5 | 480-510 | 3 |
| 460-480 | 4 | ||
| 合計 | 100 | 合計 | 100 |
データの比較可能性を確保するために、再グループ化します。
F1-間隔の統合
F2 - 承認済みの共有
| | 比重 |
|
| 工場1。 | 植物2。 |
|
| 320-360 | 17 | 13 |
| 360-400 | 44 | 37.7 |
| 400-440 | 30 | (1/3)*20+(1/3)*16=24.3 |
| 440-480 | 9 | 23.33 |
| 合計 | 100 | 100 |
タスク2 S / Nの従業員2企業の分布に関するデータ。 再編成 -
h \u003d 40千
| 会社1。 | 会社2。 |
||
| S / Nのグループ化労働者、千ルーブル。 | 数字、人 | S / Nのグループ化労働者、千ルーブル。 | 数字、人 |
| 120-140 | 8 | - | |
| 140-160 | 26 | 130-180 | 39 |
| 160-180 | 38 | 160-190 | 93 |
| 180-200 | 50 | 190-220 | 60 |
| 200-220 | 48 | 220-250 | 48 |
| 220-240 | 12 | 250-280 | 51 |
| 240-260 | 10 | 280-310 | 9 |
| 260-280 | 8 | - | |
| 合計 | 200 | 合計 | 300 |
| 会社1。 | 会社2。 |
||
| S / Nのグループ化労働者、千ルーブル。 | 数字、人 | S / Nのグループ化労働者、千ルーブル。 | 数字、人 |
| 120-160 | 34 | 120-160 | 39 |
| 160-200 | 88 | 160-200 | 113 |
| 200-240 | 60 | 200-240 | 72 |
| 240-280 | 18 | 240-280 | 67 |
| 280-320 | - | 280-320 | 9 |
| 合計 | 200 | 合計 | 300 |
タスク3
1990年の企業の労働者数と従業員数の平均リスト。 - 15317人。
産業および生産的なスタッフの総数 - 12226人。
従業員 - 3091。
199 - すべてのPPP \u003d 31159人。
スレーブを含む。 - 25132、サービング6027
概説した材料をテーブルの形で送信してください
企業PPPの中間リスト。 1990年と1996年、人
宿題
タスク4 ソ連では、専門家が大学でリリースされました:
1950 - 176.9千人。
1960 - 343.3千人。
1969年 - 564.9千人。
この業界で大学を卒業した人の中から、1950年が勉強されました - 145.9千人1960 - 228.7千人。、1969 - 295.8千人
夕方 - 1950 - 2.0
対応 - 1950 - 29.0千人。
データをテーブルの形式で送信してください。
1950年、1960年、1969年、千年のUSSRの高校卒業生の平均リスト。
| 卒業生 | 年 |
||
| 1950 | 1960 | 1969 |
|
| 合計、t。 | |||
| 日 | |||
| イブニング | |||
| 対応 | |||
| 年 | 卒業生 |
|||
| 日 | イブニング | 対応 | 合計 |
|
| 1950 | ||||
| 1960 | ||||
| 1969 | ||||
タスク5 四半期ごとの月の製品生産:
1月 - 1050万ルーブル。
2月 - 950万ルーブル。
3月 - 1200万ルーブル
大学のUSSRでは、専門家がリリースされました。
1950 - 176.9千人。
1960 - 343.3千人。
1969年 - 564.9千人。
この業界の大学を卒業した人の中から、それはうまくいきました。
1950 - 145.9千人。
1960 - 228.7千人。
1969年 - 295.8千人。
1990年の企業の労働者数と従業員数の平均リスト - 15317人
産業および生産的な担当者の総額 - 12226人、従業員 - 3091。
1996年 - すべてのPPP \u003d 31159人。 労働者を含む - 25132、従業員 - 6027。
表の形で表された材料を表す。
10.1。 統計テーブルの概念と要素
統計表含むテーブル 総合全体の数値特性1つ以上の重要な機能によると、経済分析の相互関係論理。
統計表の値は、それらです 統計報告書の資料を明確にそして全体的に覆いましょう。
沿って 外観 統計表IS 水平方向の文字列を形成する多数の水平線と垂直線が垂直に- グラフ(列、列)、一緒にテーブルのスケルトンを構成します。
他の表形式からの統計表の主な違い:
統計表は、データの経験的(統計的観察結果として得られた)の結果を含む。
主な情報の報告の結果です。
彼女は表します 統計的要約の結果は、より視覚的でコンパクトな形式で完全である。
まだ数字でいっぱいになっていない行とグラフからなるテーブル テーブルレイアウト
テーブル名(共有タイトル)
イチジク。 - 1.テーブルレイアウト
各統計表は忠実である必要があります。
テーブルの対象これは、定量的特性を特徴とする、研究の対象(地区名、都市、企業)です。
テーブルテーブル- これは、テーブルスタディオブジェクトによって特徴付けられるインジケータのシステムです。
一般名に加えて、統計表はグラフの内容を特徴付ける上位ヘッダと、表の行の内容を含む上位ヘッダも含まれています。
10.2。 統計表の種類
シンプルなテーブルグループがないテーブルは、次のリストだけです。
集約単位(リスト表)。
管理地区(領土表);
期間(時系列表)
グループ- 対象となる統計テーブルには、1つの定量的または属性機能との組み合わせ単位のグループ化が含まれています。 グループ表の凡例は、対象の特性に必要な数字で構成されています。
グループ統計表は、それらのためのコンポーネントのために研究された現象を分析するためのより有益な材料を、インジケータの数の間の大きな徴候または検出の影響を受けやすい。
組み合わせテーブル2つ以上の機能をグループ化する対象に含まれるテーブル。たとえば、2つの機能のための組み合わせテーブルは、関係の現象の説明を与えないため、2つのグループ表に置き換えられません。 組み合わせテーブルでは、符号の組み合わせの場所を任意に変更することは不可能である。 標識は重要性や研究の順序によって配置される必要があります。
利点 組み合わせテーブル シンプルと比較して、彼らはあなたが視覚的な比較を生み出し、そして重要なリンクと現象の違いを開くことを可能にすることです。
コマークテーブル定量的および属性標識の組み合わせの2つの属性(定性的)符号の合計の組み合わせ数値特性を含む表。
社会現象とプロセスを研究するとき、犯されたテーブルは最も一般的でした。 世論、レベル、ライフスタイル、社会政治システムなど
10.3。 統計表に対する操作の基本的な規則
統計表を構築するための基本的な規則:
テーブルはコンパクトで、研究された現象を直接反映したデータのみを含み、研究の目的を達成するために必要です。
デジタル材料は、テーブルを分析するときに、現象のエンティティが左から右への弦を読むことによって現象のエンティティが明らかにされたように表現されなければならない。
テーブルのタイトルとグラフと行の名前は、明確に、短い、Laconicで、完全な整数を表し、テキストの内容に有機的にフィットする必要があります。
テーブルには最終的な文字列(または列)が含まれている必要があります。
存在します 様々な方法 グラフ(文字列)という用語の結果との接続
文字列「合計」または「合計」はテーブルを完成させます。
最後の行はテーブルの1行目にあり、その用語の組み合わせが「それらの範囲」または「含む」という言葉で接続されています。
個々のグラフの名前に繰り返しの用語が含まれているか、単一の意味的負荷を伝送する場合は、結合ヘッダーを割り当てる必要があります。
検討された属性の集計単位数を特徴付けるグラフ(行)は、Failbibleの1st GRAF(文字列)である必要があります。
それらの多くがある場合は、グラフと行が番号が付けられているのに役立ちます。
国内外の統計のテーブルを記入するときは、次の条件付き通知が使用されます。
"..."(省略記号) - 現象は存在しますが、それについての情報はありません。
"0"(ゼロ) - 現象は存在しますが、その指標の値は丸め時に採用されているユニットの半分以下です。
" - "(ダッシュ) - 現象はありません。
"x"(十字) - セルは塗りつぶしの対象ではありません。
10.4。 統計表の読み取りと分析。
テーブルの読み取りと分析は、カオチックにはなく、ある程度の配列で行われるべきです。 読み方 それは研究者たちがテーブルの単語と数を読んでいると仮定します。その内容を学びました。 オブジェクトに関する最初の判断を策定しました。 テーブルの目的を計算しました。 その内容全体を理解しました。 表に記載されている現象またはプロセスの評価を行いました。
テーブル分析研究の対象を分割した科学研究の方法として シェア構造上 意味のある。
まず、テーブルの一般的な結果を調査し、次にグループ、プライベート、そしてその後、個々の行とグラフの分析に進むことをお勧めします。
構造解析表の構造の分析、以下の特性:
それを形成する観察の燃焼と単位。
被験者と標的テーブルを形成する兆候とそれらの組み合わせ。
FADの指標を持つ被験者の徴候の比率。
適切な機能の対象となる個々のグループの分析。
1つの特徴と異なる特徴に対する現象グループ間の比率と比率を特定する。
個々の群に対する結論の比較分析と定式化。
研究されている物体の開発のための埋蔵量の確立と埋蔵量の識別。
さらに、表分析は示唆されています 論理検査これらの数値またはその他の数値の特定の兆候を決定する(たとえば、会社の従業員数が105.8人に達した場合)。
検査を数える選択的計算:
グループの個別の兆候。
行またはグラフなどの合計値
統計表を分析した後のより完全で視覚的な情報については、統計的な図面が構築されます。ヒストグラム。 ダイアグラム; カートグラム、カーディンググラム、周波数ポリゴンなど
10.5。 統計研究のための統計的グラフの概念と価値
統計スケジュール- これは情報を提示する最も目に見える手段の1つであり、これは特定の指標によって特徴付けられる統計的集合体が従来の幾何学的画像または標識を使用して説明される描画である。
適切に構築されたスケジュールは統計情報を作ります:より表現的です。 思い出深い; 便利に知覚されます。
グラフィック画像を構築するときは、以下の要件に従うべきです。
スケジュールはかなり視覚的でなければなりません。
表現的で理解できなければなりません。
情報が過負荷になるべきではありません。
使用されるグラフィック画像の形式に応じて、統計的グラフは次のとおりです。ポイント; 線形; 飛行機。
に スポットグラフグラフィック画像として、一連の点が適用されます。
に 線形グラフグラフィック画像は行です。
ために 平面図グラフィック画像は幾何学的形状です:長方形、正方形、円。
統計チャートは次の要素を区別します。グラフィックフィールド グラフィックイメージ。 空間的および大規模なガイドライン。 スケジュールの説明
· グラフィックフィールドそれが実行される場所。この紙、地理的地図、位置計画などのシート グラフのグラフはそのフォーマット(締約国のサイズと割合)によって特徴付けられます。 グラフのフィールドのサイズはその目的によって異なります。 視覚の最も最適なことは、アスペクト比が1:1.3から1:1.5のグラフです( ルール「ゴールデンセクション」)。
· グラフィックこれらは、統計データ(線、点、長方形、正方形、円などが示されている)を持つ象徴的な符号です。 体積数値はグラフィック画像として突き出ています。 グラフは、シルエットやオブジェクトのパターンの形で非幾何学的な数字を使用します。
· 空間ランドマークグラフフィールド上のグラフィック画像の配置を決定します。 それらは座標グリッドまたは輪郭線によって指定され、研究中の指標の値に対応する部分のグラフを分割する。
· 大規模なランドマーク統計グラフィックはグラフィック画像を与えます 定量的有意性これはシステムを使って送信されます 大規模スケール
· スケールグラフィック- これは数値の数値のグラフィックへの転送の尺度です(たとえば、1cmは100万ルーブルに対応します。)。 同時に、数字単位に撮影された線のセグメントが長いほど、スケールが大きくなります。
· 大規模な- ライン、そのポイントは特定の数字として読み込まれます。 研究された指標のレベルが検討されているスケールは、原則として検討されています。スケールに適用された最後の数字は最大レベルをわずかに超えているため、そのカウントダウンはこのスケールで実行されます。 スケジュールを構築するときは、スケールスケールが許可されています。
· グラフィックの説明- これはその内容の説明です。
見出しグラフィック
大規模スケールの説明
個々のグラフィック画像要素の説明
10.6。 統計グラフの分類
統計グラフは、線形、体積測定、平坦で使用されるグラフィック画像、および図形および統計カードへの画像タスクの方法に応じて、(図2)に分類される(図2)。
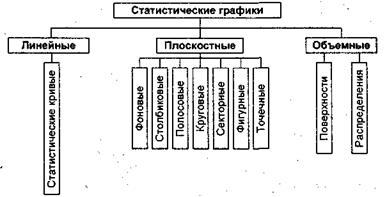

イチジク。 - 統計グラフの分類
10.7。 チャート、統計マップ、ヒストグラム
A.図統計情報が幾何学的形状または象徴的な符号によ\u200b\u200bって描かれている図面。
チャートは、互いに独立したさまざまな側面(空間、一時的など)の視覚的比較に使用されます。 この場合、凝集体の比較は、任意の有意な変異符号に従って行われる。
比較図 -統計的骨材の徴候の比を示す。
ダイナミクスダイアグラム- 時の現象の変化を示します。
通信ダイアグラム- 他の機能の機能依存性を表示する
B.統計カード- グラフィックの種類は、集合体の管理上または地理的部門が対象となる回路図地図上の統計データの内容を示しています。 統計的マップは、輪郭地理マップ上の統計データの従来の画像、すなわち 統計データの空間配置または空間的有病率を示す。
統計マップはカートグラムとCardageGramに分けられます。
カートグラム -これは概略です 地理的な地図その上に、地図に適用される領土分割部の各ユニット内の任意の程度の繊細さ、ドットまたは強度のハッチングが示される。
オン マルチグラム、カードの背景には、図の要素があります。 CardageGramの前の利点は、それが異なる地域の下で指標の大きさを考えているだけでなく、研究されている指標の空間的配置も描写することです。 CardageGramの例は、都市が指定されている政治地図です。 幾何学的図 さまざまなタイプの 住民の数によって異なります。
B. Varzaraチャート(V.e. Warzar、1851-1940)はグラフィック画像のための長方形の数字です そのうちの3つのインジケータ、そのうちの1つは他の2つの仕事です(集団はその領土上の人口密度の産物です)(図3)。 そのような各長方形では、ベースは要因インジケータの1つに比例し、その高さは2番目のファクトリインジケータに対応します。 矩形の面積は3番目のインジケータの値に等しい。これは2番目の作業です。 さまざまなインジケータに関連する複数の長方形が多数ある場合は、製品インジケーターのサイズだけでなく、要素の値も比較できます。賢い備えます 座標グリッドに描かれた互いの互いの長方形に隣接して、いくつかの分配または現象の力学を表示するために使用されます。 この図は、この間隔の周波数に正比例した高さの四角形の延長された長方形です。
10.8。 統計グラフの例
統計表 - 研究された変換の定量的特性 統計表では、統計的観察結果が明確に反映されています。
各統計表では区別します テーブルベアリングテーブル .
卓球科 - 材料群が行ったメイン(主な)会計特徴は、統計表の左側にあります。
テーブルをベーキングしました - 財務省を特徴付ける会計機能は、縦列のタイトルの表の右側にあります。
統計表をコンパイルする際には、次のものが含まれます。
表のタイトルはその内容を開示する必要があります
タイトル表は、与えられたデータの測定単位を示します
表形式の被写体はテーブルの左側(水平線)の左側にあり、右側の部分(垂直線で)
ゼロ記号は「ダッシュ」の符号を示します
一般的で注がれた最終弦の存在
使用されている機能の数とそれらのグループ化が異なる 単純なグループと組み合わせ テーブル
簡単で 統計表の材料は1回の入場によってグループ化され、そのような表は一般的なデータ概要を表します。
グループテーブルに - いくつかの独立した兆候によって特徴付けられる対象。
組み合わせテーブルで - いくつかの相互に関連する特徴を特徴とする対象。 分析用語のそのような表は最も価値があります。
レイアウトシンプルテーブル
ローカライズ傷害の分布
グループテーブルのレイアウト
診断、性別、年齢のための病院からの処分の組成
組み合わせテーブルの中でモック
異なる年齢と性別の子供の間の心臓欠陥の分布
|
両方とも |
両方とも |
両方とも |
両方とも |
||||||||||||
|
ハートパルク壁 | |||||||||||||||
|
心臓病プリ - | |||||||||||||||
ステージII。 材料コレクション(統計観測)
統計的観察は、特別会計医療文書上の研究された単位の登録です。
統計的観察 集約単位の完全性を考慮して、時間の事実の説明と観察方法を考慮しています。
|
分類の兆候 |
観測の種類 |
品種 |
|
1.時の会計要因によって | ||
|
一度 | ||
|
2.集約単位のカバレッジの完全性について |
固体 | |
|
際どない |
a)選択的 |
|
|
b)メインアレイ |
||
|
c)モノグラフィ |
||
|
展望の観測方法 |
直販 | |
|
データをキャッチしたAnamNesticメソッド |
現在の観察 (永久)それは、生活環境、医療の状態などに応じて急速に細かい現象の研究に使用されています。この体系的な一定期間、統計データはそれを登録することによって統計的データを収集します発生からのものです(出生率会計、死亡率、罹患率、怪我、入院)。
ワンタイム観測 (simultan)現象が急激に変化する傾向がない場合、ゆっくりと変化する現象を学習するときに使用されます。データロギングはある時点でデータロギングを実行します。 ワンタイム観察は、現象の静的、すなわち、研究されている現象の単一の写真(人口の国勢調査、民主共用検査、医療機関の国勢調査な\u200b\u200bど)のようなものです。
完全性の際、カバレッジは堅実で無給の監視によって区別されます。
しっかりした観察 一般的な人口を構成するすべてのケースの登録を提供します。 固体法は、生まれた、死んだ、診療所に適用された、患者の数、その他の患者の数に関する情報を収集し、その他の患者の数は比較的限られた数の会計徴候の集積物の集まりに特徴的です。詳細な分析を許可しません。
他の非観察方法で 観察の対象物全体の特性によると、すべての落ち着きユニットが考慮されているわけではありません。 有意な観察にはいくつかの利点があります。ボリュームが少なく、その実装のための強さやツールが必要です。これは、事実、つまり研究プログラムを拡大するためのより高度な会計方法を適用することができます。 研究の対象とレートの性質に応じて、断続的な研究は異なる方法で編成されています。