Vkladanie objektov - Výučba informatiky. Prenos údajov z hárkov rovnakého súboru. Nahradenie hodnôt za podmienok
Čo sa dalo vyriešiť v programe MS Excel, je možné podľa očakávaní implementovať do tabuliek Google. Ale početné pokusy o riešenie problémov pomocou vášho obľúbeného vyhľadávacieho nástroja viedli iba k novým otázkam a takmer nulovým odpovediam.
Preto sa rozhodlo uľahčiť život iným a osláviť sa.
Stručne o hlavnej
Aby program Excel alebo tabuľka (tabuľka Google) pochopila, že to, čo je napísané, je vzorec, musíte do panela vzorcov vložiť znak „\u003d“ (obrázok 1).- alfanumerický (PÍSMENO \u003d STĹPEC; ČÍSLO \u003d RIADOK), napr. „A1“.
- v štýle R1C1 sú v systéme R1C1 riadky aj stĺpce označené číslami.
Tam, kde napíšeme „\u003d vzorec“, napríklad \u003d SUM (A1: A10) a zobrazí sa naša hodnota.
Všeobecný princíp fungovania RC vzorcov je znázornený na obrázku 2.

Obrázok 2
Ako môžete vidieť na obrázku 3, hodnoty buniek sú relatívne k bunke, do ktorej bude vzorec so znamienkom rovnosti napísaný. Kvôli zachovaniu estetického vzhľadu vzorcov obsahujú tieto symboly, ktoré je možné vynechať: RC \u003d RC.

Obrázok 3
Rozdiel medzi obrázkami 2 a 3 je ten, že obrázok 3 je všeobecná formulácia, ktorá nie je viazaná na riadky a stĺpce (pozrite sa na hodnoty riadkov a stĺpcov), čo sa o obrázku 2 povedať nedá. Ale štýl RC v tabuľka sa používa hlavne na písanie skriptov javascript.
Typy odkazov (typy adresovania)
Na označenie buniek sa používajú odkazy, ktoré sú 3 typov:- Relatívne odkazy (príklad, A1);
- Absolútne odkazy (napríklad $ A $ 1);
- Zmiešané odkazy (napríklad $ A1 alebo A $ 1, sú polovičné relatívne, polovičné absolútne).
Relatívne odkazy
Relatívny odkaz si „pamätá“, v akej vzdialenosti (v riadkoch a stĺpcoch) ste klikli RELATÍVNE na pozíciu bunky, kam ste vložili „\u003d“ (posun v riadkoch a stĺpcoch). Potom potiahnite rukoväť automatického dokončovania a tento vzorec sa skopíruje do všetkých buniek, cez ktoré sme sa pretiahli.Absolútne odkazy
Ako už bolo spomenuté vyššie, ak presuniete vzorec obsahujúci relatívne odkazy na značku automatického dopĺňania, tabuľka prepočíta ich adresy. Ak vzorec obsahuje absolútne odkazy, ich adresa zostane nezmenená. Jednoducho povedané - absolútny odkaz vždy smeruje do rovnakej bunky.Ak chcete, aby bol relatívny odkaz absolútny, jednoducho vložte znak „$“ pred písmeno stĺpca a adresu riadku, napríklad $ A $ 1. Viac rýchly spôsob - vyberte relatívny odkaz a stlačte jedenkrát kláves „F4“, zatiaľ čo tabuľka umiestni znak „$“ sám. Ak stlačíte kláves „F4“ druhýkrát, odkaz sa zmení na zmiešaný typ A $ 1, ak sa tretíkrát - $ A1, ak štvrtýkrát - odkaz znova stane relatívnym. A tak v kruhu.
Zmiešané odkazy
Zmiešané odkazy sú z polovice absolútne a z polovice relatívne. Znak dolára sa v nich zobrazuje buď pred písmenom stĺpca, alebo pred číslom riadku. Toto je najťažšie pochopiteľný typ odkazu. Napríklad bunka obsahuje vzorec "\u003d A $ 1". Referencia A $ 1 je relatívna v stĺpci A a absolútna v riadku 1. Ak presunieme tento vzorec nadol alebo nahor na značku automatického dopĺňania, odkazy vo všetkých kopírovaných vzorcoch budú smerovať do bunky A1, to znamená, že sa budú správať ako absolútne. Ak však ťaháme doprava alebo doľava, odkazy sa správajú ako relatívne, to znamená, že tabuľka začne prepočítavať svoju adresu. Vzorce vytvorené automatickým dokončovaním teda budú používať rovnaké číslo riadku ($ 1), ale bude sa meniť doslovná hodnota stĺpca (A, B, C ...).Pozrime sa na príklad sčítania buniek vynásobením určitým koeficientom.
Tento príklad predpokladá prítomnosť hodnoty koeficientu v každej vypočítanej bunke (bunky D8, D9, D10 ... E8, F8 ...). (Obrázok 4).
Červené šípky ukazujú smer natiahnutia pomocou plniacej rukoväte vzorca, ktorá je v bunke C2. Vo vzorci si všimnite zmenu v bunke D8. Po roztiahnutí sa zmení iba číslo, ktoré symbolizuje reťazec. Natiahnutím doprava sa zmení iba stĺpec.

Obrázok 4
Poďme si príklad zjednodušiť pomocou znaku $ (obrázok 5).
Obrázok 5
Nie vždy je však potrebné zmraziť všetky stĺpce a riadky, niekedy sa použije iba zmrazenie riadkov alebo iba stĺpcov (obrázok 6).
Obrázok 6
O všetkých vzorcoch si môžete prečítať na oficiálnych webových stránkach support.google.com
Dôležité: Údaje, ktoré je potrebné spracovať vo vzorcoch, by sa nemali nachádzať rôzne dokumenty, to sa dá urobiť iba pomocou skriptov.
Chyby vzorca
Ak vzorec nesprávne napíšete, upozorní vás na to poznámka o syntaktickej chybe vo vzorci (obrázok 7).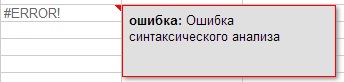
Obrázok 7
Aj keď chyby môžu byť nielen syntaktické, ale napríklad aj matematické, ako napríklad delenie 0 (obrázok 7) a ďalšie (obrázok 7.1, 7.2, 7.3). Ak chcete zobraziť poznámku, ktorá ukazuje, ku ktorej chybe došlo, umiestnite kurzor myši na červený trojuholník v pravom hornom rohu chyby.
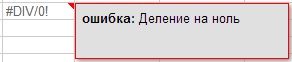
Obrázok 7.1
Obrázok 7.2
Obrázok 7.3
Pre uľahčenie čítania tabuľky zafarbíme všetky bunky vzorcami na fialovo.
Ak chcete vzorce zobraziť „naživo“, stlačte klávesovú skratku Ctrl + alebo v hornom menu vyberte Zobraziť (Zobraziť)\u003e Všetky vzorce. (Obrázok 8).

Obrázok 8
Ako sa píšu vzorce
Existujú rozdiely vo formulácii vzorcov v príručke a vo vzorcoch, ktoré sa v súčasnosti používajú. Spočívajú v tom, že namiesto „čiarky“, ktorá sa v mnohých vzorcoch používala skôr, sa už používa „bodkočiarka“ (zmeny sa udiali pred viac ako pol rokom).Ak chcete vidieť, na čo vzorec odkazuje na tejto stránke (obrázok 9), musíte kliknúť na panel vzorcov vpravo od štítku Fx (Fx sa nachádza v hlavnej ponuke vľavo).
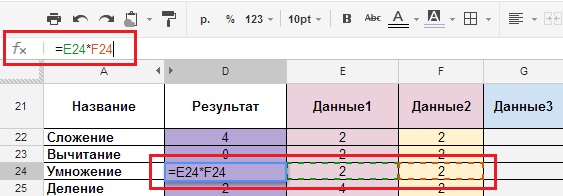
Obrázok 9
DÔLEŽITÉ: Aby vzorce správne fungovali, musia byť napísané latinskými písmenami. Ruština (cyrilika) „A“ alebo „C“ a latinka „A“ alebo „C“ pre vzorec sú dve rôzne písmená.
Vzorce
Aritmetické vzorce.
Samozrejme, nikto nebude popisovať večné operácie sčítania, odčítania atď., Ale pomôže pochopiť úplne základné veci. Niekoľko príkladov vám ukáže, ako fungujú v tomto prostredí. Všetky vzorce sú uvedené v dokumente, ktorého odkaz je uvedený na konci článku, ale zastavíme sa iba pri snímkach obrazovky.Sčítanie, odčítanie, násobenie, delenie.
- Popis: Vzorce pre sčítanie, odčítanie, násobenie a delenie.
- Typ vzorca: „Cell_1 + Cell_2“, „Cell_1-Cell_2“, „Cell_1 * Cell_2“, „Cell_1 / Cell_2“
- Samotný vzorec: \u003d E22 + F22, \u003d E23-F23, \u003d E24 * F24, \u003d E25 / F25.
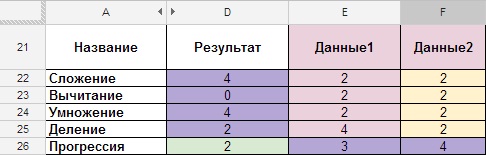
Obrázok 10
Progresia.
- Popis: Vzorec na zväčšenie všetkých nasledujúcich buniek o jednu (číslovanie riadkov a stĺpcov).
- Typ vzorca: \u003d Predchádzajúca bunka + 1.
- Samotný vzorec: \u003d D26 + 1
Obrázok 11
Zaokrúhľovanie.
- Popis: Vzorec na zaokrúhlenie čísla v bunke.
- Typ vzorca: \u003d ROUND (bunka s číslom); počítadlo (koľko číslic musí byť zaokrúhlených za desatinnou čiarkou).
- Samotný vzorec: \u003d KOLO (E28; 2).
Obrázok 12
Položka „ROUND“ je zaokrúhlená na matematické zákony, ak je za desatinnou čiarkou číslica 5 alebo viac, potom sa celá časť zvýši o jednu, ak je 4 alebo menej, potom zostane nezmenená, môžete ju tiež zaokrúhliť pomocou ponuky FORMÁT -\u003e Čísla -\u003e " 1 000,12 "2 desatinné miesta (obrázok 13). Ak potrebujete viac znakov, musíte kliknúť na FORMÁT -\u003e Čísla -\u003e Personalizované desatinné miesto -\u003e A určiť počet znakov.
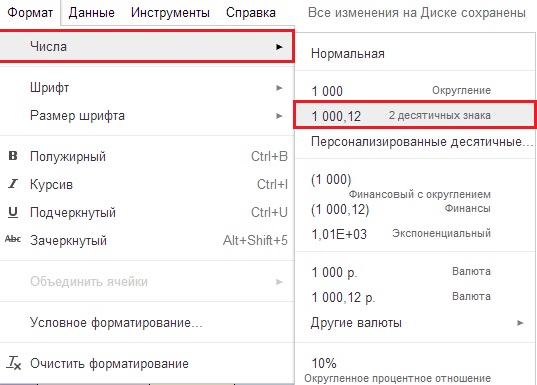
Obrázok 13
Množstvo, ak bunky nie sú postupné.
Asi najznámejšia vlastnosť- Popis: súčet čísel, ktoré sú v rôznych bunkách.
- Typ vzorca: \u003d SUMA (number_1; number_2;… number_30).
- Samotný vzorec: "\u003d SUMA (E30; H30)" prepísať ";" ak rôzne bunky.
(Obrázok 14).
Množstvo, ak sú bunky postupné.
- Popis: súčet čísel, ktoré nasledujú za sebou (postupne).
- Typ vzorca: \u003d SUMA (číslo_1: číslo_N).
- Samotný vzorec: \u003d SUMA (E31: H31) "zapísať": "ak ide o spojitý rozsah.
- Počiatočné údaje máme v rozsahu buniek E31: H31 a výsledok v bunke D31 (obrázok 15).
Obrázok 15
Priemerná.
- Popis: Rozsah čísel sa sčíta a vydelí počtom buniek v rozsahu.
- Typ vzorca: \u003d PRIEMER (bunka s číslom alebo číslom_1; bunka s číslom alebo číslom_2; ... bunka s číslom alebo číslom_30).
- Samotný vzorec: \u003d PRIEMERNÝ (E32: H32)
Obrázok 16
Samozrejme, existujú aj ďalšie, ale ideme ďalej.
Textové vzorce.
Z veľkého množstva textových vzorcov, pomocou ktorých si s textom môžete robiť, čo chcete, je podľa môjho názoru najpopulárnejší vzorec na „lepenie“ textových hodnôt. Existuje niekoľko možností jeho implementácie:Lepenie textových hodnôt (vzorec).
- Popis: „lepenie“ textových hodnôt (možnosť A).
- Typ vzorca: \u003d CONCATENATE (bunka s číslom / textom alebo textom_1; bunka s číslom / textom alebo textom_2;…, bunka s číslom / textom alebo textom_30).
- Samotný vzorec: \u003d KONCATENÁT (E36; F36; G36; H36).
Pomocou Dokumentov Google často uskutočňujú prieskumy zamestnancov alebo zostavujú prieskumy verejnej mienky prostredníctvom formulárov Google (jedná sa o špeciálne formuláre, ktoré je možné vytvoriť v ponuke Vložiť-\u003e Formulár. Po vyplnení formulára sa údaje zobrazia v tabuľke. A potom, používajú rôzne vzorce na prácu s údajmi, napríklad na lepenie celého mena).
Obrázok 17
Lepenie číselných hodnôt.
- Popis: „lepenie“ textových hodnôt ručne, bez použitia špeciálnych funkcií (možnosť B - ručné písanie vzorca, zložitosť vzorca je akákoľvek.).
- Typ vzorca: \u003d bunka s číslom / textom 1 & "" & bunka s číslom / textom 2 & "" & bunka s číslom / textom 3 & "" & bunka s číslom / textom 4 ("" - medzera, & znamienko znamená lepenie , všetky textové hodnoty sú napísané v úvodzovkách „“).
- Samotný vzorec: \u003d E37 & "" & F37 & "" & G37 & "" & H37.
Obrázok 18
Spojenie číselných a textových hodnôt.
- Popis: „lepenie“ textových hodnôt ručne, bez použitia špeciálnych funkcií (variant C - zmiešaný typ, zložitosť vzorca je ľubovoľná).
- Typ vzorca: \u003d "text_1" & cell_1 & "text_2" & cell_2 & "text_3" & cell_3
- Dôležité: všetok text, ktorý bude napísaný v tvare „“, sa pre vzorec nezmení.
- Samotný vzorec: \u003d "1 viac" & E38 & "použitie" & F38 & "ako USA" & G38.
Lepíme textové a číselné hodnoty.
Obrázok 19
LOGICKÉ A INÉ
Prenos údajov z hárkov rovnakého súboru.
Prišli sme k najzaujímavejším, podľa môjho názoru, funkciám: LOGICKÉ A INÉ.Jeden z najužitočnejších vzorcov:
- Popis: prenos údajov z ľubovoľných hárkov rovnakého súboru (v programe Excel môžete obidva prenášať z hárka jedného zošita do iného hárka rovnakého zošita alebo z hárka jedného zošita do hárka iného zošita).
- Typ vzorca: \u003d "Názov_listu"! bunka_1
- Samotný vzorec: \u003d Údaje! A15 (Údaje sú hárok, A15 je bunka na tomto hárku).
Obrázok 20
Obrázok 20.1
Pole vzorcov.
Väčšina tabuľkových programov obsahuje dva typy maticových vzorcov: „multi-cell“ a „single-cell“.Tabuľky Google rozdeľujú tieto typy na dve funkcie: POKRAČOVAŤ a ARRAYFORMULA.
Vzorce s poľami viacerých buniek umožňujú, aby vzorec vrátil viac hodnôt. Môžete ich použiť bez toho, aby ste o tom vedeli, jednoducho zadaním vzorca, ktorý vráti viac hodnôt.
Jednobunkové maticové vzorce umožňujú písať vzorce pomocou vstupu poľa skôr ako výstupu. Keď vložíte vzorec do funkcie \u003d ARRAYFORMULA, môžete poliam alebo rozsahom odovzdať funkcie a operátory, ktoré zvyčajne používajú iba argumenty iných ako polia. Tieto funkcie a operátory sa použijú, jeden pre každú položku v poli, a vráti nové pole so všetkým výstupom.
Ak chcete preskúmať podrobnejšie, mali by ste navštíviť stránku support.google.
Zjednodušene povedané, ak chcete pracovať so vzorcami, ktoré vracajú súbory údajov, musíte ich uzavrieť do poľa vzorcov, aby ste sa vyhli chybám syntaxe.
Sčítanie buniek s podmienkou IF.
Aby sme mohli pracovať s logickými vzorcami, ktoré zvyčajne obsahujú veľké množiny údajov, sú umiestnené v poli vzorcov ARRAYFORMULA (vzorec).- Popis: Súčet buniek s podmienkou IF (vzorec SUMIF).
- Typ vzorca: \u003d SUMIF („Tabuľka“! Rozsah; kritériá; „List“! Celkový_rozsah)
Úloha, aký bude mať fiškálny doklad po vytlačení (stačí pridať produkty 3 kupujúcich a zistiť počet produktov celkovo pre každú pozíciu)?
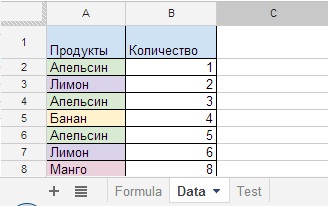
Obrázok 21
Počiatočné údaje máme v údajovom hárku (obrázok 21) a výsledok v hárku vzorcov v stĺpci D (obrázok 22). Stĺpce E, F, G zobrazujú argumenty použité vo vzorci a stĺpec H zobrazuje všeobecný pohľad na vzorec, ktorý je v stĺpci D, a počíta výsledok.

Obrázok 22
Vyššie uvedený príklad ukazuje všeobecný pohľad na to, ako vzorec „Sum If“ pracuje s jednou podmienkou, ale najčastejšie sa používa „Sum IF“ (s viacerými podmienkami).
Sčítanie buniek IF, veľa podmienok.
Naďalej uvažujeme o probléme s výrobkami na inej úrovni.Párty sa práve začína a po zavolaní svojim priateľom začnete chápať, že alkoholu nebude dosť. A musíte si ho kúpiť. Každý z vašich priateľov by si mal so sebou vziať silný nápoj. Musíte zistiť počet fliaš piva, ktoré musíte priniesť, a dať úlohu svojim priateľom.
- Popis: súčet IF (s viacerými podmienkami).
- Typ vzorca: \u003d SUMIF („Údaje“! Rozsah_1 a „Údaje“! Rozsah_2; kritériá_1 & kritérium_2; „Údaje“! Rozsah_obsahu).
- Samotný vzorec: \u003d (ARRAYFORMULA (SUMIF ((Data! E: E & Data! F: F); (B53 & C53); Údaje! G: G))))

Obrázok 23. Obrázok č
Predpokladajme, že na hárku vzorcov by v bunke B53 (kritérium_1 \u003d pivo) mal byť názov nápoja a v bunke C53 (kritérium_2 \u003d 2) je počet priateľov, ktorí prinesú pivo. Výsledkom bude, že bunka D53 bude obsahovať výsledok, ktorý si vyžaduje zakúpenie 15 fliaš piva. (Obrázok 23.1), to znamená, že vzorec určí množstvo na základe dvoch kritérií - piva a počtu priateľov.
Obrázok 23.1
Ak existuje viac takýchto pozícií, riadky 16 a 21 (obrázok 24), potom sa počet bublín v stĺpci G spočíta (obrázok 24.1).

Obrázok 24. Obrázok č
Celkom:
Obrázok 24.1
Teraz uveďme zaujímavejší príklad:
Ha ... párty pokračuje a vy si pamätáte, že potrebujete tortu, ale nie ľahkú, a supermega tortu s rôznymi koreninami, ktoré sú, ako by to šťastie malo, tiež zašifrované číslami. Výzvou je kúpiť korenie v správnom počte vreciek každého korenia. Šéfkuchár zašifroval požadované množstvo v tabuľke (obrázok 25.1), stĺpcoch A a B (v susedných stĺpcoch robíme naše výpočty).Každé korenie má svoje sériové číslo: 1,2,3,4. (Obrázok 25).
Obrázok 25
Našou úlohou je spočítať počet opakovaných hodnôt, v našom prípade sú to čísla od 1 do 4 v stĺpci B a určiť percento každého z korenín.
- Popis: Počítanie počtu identických číslic vo veľkých poliach za ďalších podmienok.
- Typ vzorca: COUNT IF ('Formula'! Range_A55: A61 + 'Formula'! Range_B55: B61; ConditionA “Spices” + ConditionB “číslo od 1 do 4”; list „Formula“! Range_B55: B61) / ConditionB “číslo od 1 až 4 ")
- Samotný vzorec: \u003d ((ARRAYFORMULA (SUMIF ("Formula"! $ A $ 55: $ A $ 61 & "Formula"! $ B $ 55: $ B $ 61; $ F $ 55 & $ E59; "Formula") ! $ B $ 55: $ B $ 61))) / $ E59)
- Popis: Vypočíta percento korenia.
- Typ vzorca: Suma * 100% / Celková_počet
- Samotný vzorec: \u003d F58 * $ G $ 56 / F $ 56

Obrázok 25.1
Nakoniec máme počet opakovaní a percento.
Aby ste vzorec napísali správne, musíte úplne pochopiť, čo máte, čo chcete získať a v akej podobe. Možno budete musieť zmeniť vzhľad počiatočných údajov.
Prejdime k ďalšiemu príkladu
Počítanie hodnôt v zlúčených bunkách.
Ak vzorce používajú hodnoty v „zlúčených bunkách“, je označená prvá bunka pre zlúčené údaje, v našom prípade je to stĺpec F a bunka F65 (obrázok 26)
Obrázok 26.
A nakoniec sme sa dostali k najhorším vzorcom.
Spočíta počet čísel v zozname argumentov.
Existuje niekoľko typov takýchto výpočtov, sú vhodné pre veľké tabuľky, v ktorých musíte počítať počet rovnakých slov alebo počet čísel. Ale so správnym porozumením týchto vzorcov môžete s nimi robiť také zázraky, ako napríklad: počítanie slov bez zohľadnenia slov výnimiek. Príklady nájdete nižšie.- Popis: Spočítava počet buniek obsahujúcich čísla bez textových premenných.
- Typ vzorca: COUNT (hodnota_1; hodnota_2; ... hodnota_30)
- Samotný vzorec: \u003d COUNT (E45; F45; G45; H45)
Obrázok 27.
Nepočítajú sa ani bunky obsahujúce text a čísla.
Obrázok 27.1.
Počítanie počtu buniek obsahujúcich čísla s textovými premennými.
- Popis: Spočítava počet buniek obsahujúcich čísla s textovými premennými.
- Typ vzorca: COUNTA (hodnota_1; hodnota_2;… hodnota_30)
- Samotný vzorec: \u003d COUNTA (E46: H46)
Obrázok 28.
Vzorec tiež počíta bunky obsahujúce iba interpunkčné znamienka, tabulátory, ale nepočíta prázdne bunky.
Obrázok 28.1
Nahradenie hodnôt za podmienok.
- Opis: Nahradenie hodnôt za podmienok.
- Typ vzorca: "\u003d IF (AND ((Podmienka1); (Podmienka2)); Výsledok je 0, ak sú splnené podmienky 1 a 2; ak nie, potom je výsledok 1)"
- Samotný vzorec: "\u003d IF (AND ((F73 \u003d 5); (H73 \u003d 5)); 0; 1)"
Obrázok 29.
Obrázok 29.1
Poďme si to komplikovať.
Spočítajte počet buniek, v ktorých je napísaný časový rámec, okrem slov „automatická odpoveď“, „obsadené“, „-“.
- Typ vzorca: "\u003d COUNTA (Range_A) -COUNTIF (Range_A;" automatická odpoveď ") - COUNTIF (Range_A;" - ") - COUNTIF (Range_A;" zaneprázdnený ")"
- Samotný vzorec: \u003d COUNTA ($ E74: $ H75) -COUNTIF ($ E74: $ H75; "odpoveď") - COUNTIF ($ E74: $ H75; "-") - COUNTIF ($ E74: $ H75; "zaneprázdnený) „)

Obrázok 30.
Dostali sme sa tak na koniec nášho malého vzdelávacieho programu o vzorcoch v aplikácii Google SpreadSheet a dúfam, že som objasnil niektoré aspekty analytickej práce so vzorcami.
Úprimne povedané, vzorce boli doslova ťažko vybojované. Každá z nich vznikla v priebehu času. Dúfam, že sa vám môj článok a príklady v ňom páčili.
A na záver ako darček. A nech mi vývojári odpustia!
Vzorec „ZABÍJAČ DOKUMENTOV“.
Ak potrebujete dokument navždy skryť pred zvedavými očami, potom je tento vzorec pre vás.Samotný vzorec: "\u003d (ARRAYFORMULA (SUMIF ($ A: $ A & $ C: $ C; $ H: $ H & F $ 2; $ C: $ C)))". $ H: $ H riadi distribúciu vzorca. Po spustení fomluly (obrázok 31) dole v bunkách sa začne množiť ďalšia funkcia POKRAČOVAŤ (bunka; riadok; stĺpec).

Obrázok 31.
Vzorec sa cyklicky pridáva do celého stĺpca vzorca. Ak chcete dokument zabiť, musíte to trochu vyskúšať, vytvoriť N-tý počet buniek a do prvých buniek N-tého počtu stĺpcov napísať vzorec. Všetko! Nikto iný nemôže dokument opraviť a skontrolovať!
Na stránke pomocníka Google sa hovorí o pracovnom zaťažení a obmedzeniach -
Hlavným účelom tabuliek je usporiadať všetky druhy výpočtov. Už viete, že:
- Výpočet je proces výpočtu podľa vzorcov;
- Vzorec začína znamienkom rovnosti a môže obsahovať znaky operácie, čísla, odkazy a vstavané funkcie. Najprv zvážime problémy spojené s organizáciou výpočtov v tabuľkách.
3.2.1. Relatívne, absolútne a zmiešané odkazy
Odkaz označuje bunku alebo rozsah buniek, ktoré chcete použiť vo vzorci. Odkazy umožňujú:
- použitie v jednom vzorci, ktorý je v rôznych častiach tabuľky;
- použite hodnotu jednej bunky vo viacerých vzorcoch. Existujú dva hlavné typy odkazov:
1) relatívne - v závislosti od polohy vzorca;
2) absolútne - nezávisí od polohy vzorca.
Rozdiel medzi relatívnymi a absolútnymi odkazmi sa objaví, keď skopírujete vzorec z aktuálnej bunky do iných buniek.
Relatívne odkazy. Relatívny odkaz vo vzorci určuje umiestnenie dátovej bunky vzhľadom na bunku, v ktorej je vzorec napísaný. Keď zmeníte pozíciu bunky obsahujúcej vzorec, zmení sa odkaz.
Zvážte vzorec \u003d A1 ^ 2 napísaný v bunke A2. Obsahuje relatívny odkaz na A1, ktorý je vnímaný stolný procesor takto: obsah bunky, ktorá je o jeden riadok vyšší ako ten, v ktorom sa nachádza vzorec, by mal byť na druhú.
Keď kopírujete vzorec pozdĺž stĺpca a pozdĺž riadku, relatívna referencia sa automaticky upraví takto:
- posun o jeden stĺpec vedie k zmene odkazu na jedno písmeno v názve stĺpca;
- posun o jeden riadok vedie k zmene odkazu na číslo riadku o jeden.
Napríklad keď kopírujete vzorec z bunky A2 do buniek B2, C2 a D2, relatívna referencia sa automaticky zmení a vyššie uvedený vzorec sa zmení na: \u003d B1 ^ 2, \u003d C1 ^ 2, \u003d D1 ^ 2. Pri kopírovaní rovnakého vzorca do buniek AZ a A4 dostaneme \u003d A2 ^ 2, \u003d AZ ^ 2 (obr. 3.4).
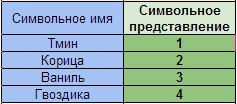
Príklad 1. V 8. ročníku sme uvažovali o probléme populácie určitého mesta, ktorá sa každoročne zvyšuje o 5%. Vypočítajme odhadovanú populáciu mesta v nasledujúcich 5 rokoch v tabuľkách, ak je to tento rok 40 000 ľudí.
Zadajme do tabuľky originál, zadajme vzorec \u003d B2 + 0,05 * B2 do bunky OT s relatívnymi odkazmi; skopírujte vzorec z bunky OT do rozsahu buniek B4: B7 (obr. 3.5). 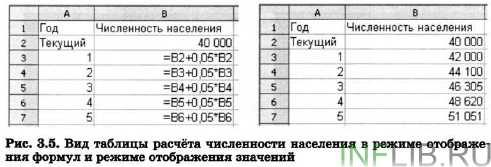
My (podľa stavu úlohy) sme vykonali ročný výpočet populácie podľa rovnakého vzorca, ktorého počiatočné boli vždy v bunke umiestnenej v rovnakom stĺpci, ale o riadok vyššie ako výpočtový vzorec. Pri kopírovaní vzorca obsahujúceho relatívne referencie sa požadované zmeny vykonali automaticky.
Absolútne odkazy. Absolútny odkaz vo vzorci sa vždy vzťahuje na bunku na konkrétnom (pevnom) mieste. V absolútnej referencii je pred každé písmeno a číslo umiestnené $, napríklad $ A $ 1. Zmena polohy bunky obsahujúcej vzorec nezmení absolútnu referenciu. Pri kopírovaní vzorca pozdĺž línií a stĺpcov sa absolútna referencia neupravuje (obr. 3.6). 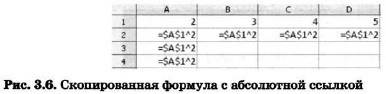
Príklad 2. Istý občan si otvorí účet v banke za 10 000 rubľov. Bol informovaný, že každý mesiac sa výška vkladu zvýši o 1,2%. Za účelom zistenia možnej výšky a prírastku výšky vkladu po 1, 2, ..., 6 mesiacoch vykonal občan nasledujúce výpočty (obr. 3.7). 
Zmiešané odkazy. Zmiešaná referencia obsahuje buď absolútne adresný stĺpec a relatívne adresný reťazec ($ A1), alebo relatívne adresný stĺpec a absolútne adresný reťazec (A $ 1). Keď zmeníte pozíciu bunky obsahujúcej vzorec, zmení sa relatívna časť adresy, ale absolútna časť adresy sa nezmení.
Pri kopírovaní alebo vypĺňaní vzorca pozdĺž riadkov a pozdĺž stĺpcov sa relatívna referencia automaticky upraví a absolútna referencia sa neupraví (obrázok 3.8). 
Ak chcete previesť odkaz z relatívneho na absolútny a naopak, môžete ho vybrať vo vstupnom riadku a stlačiť kláves F4 (Microsoft Office Excel) alebo Shift + F4 (OpenOffice.org Calc). Ak vyberiete relatívnu referenciu, napríklad A1, pri prvom stlačení tejto klávesy (kombinácia klávesov) sa riadok aj stĺpec nastaví na absolútne referencie ($ A $ 1). Na druhé kliknutie získa absolútny odkaz iba reťazec (A $ 1). Na tretie kliknutie získa absolútny odkaz iba stĺpec ($ A1). Ak znovu stlačte kláves F4 (kombinácia klávesov Shift + F4), potom sa pre stĺpec a riadok nastavia relatívne odkazy (A1).
Príklad 3. Je potrebné zostaviť tabuľku sčítania čísel prvých desiatich, to znamená vyplniť tabuľku tohto formulára: 
Pri vypĺňaní ktorejkoľvek bunky tejto tabuľky sa zodpovedajúce hodnoty buniek stĺpca A a riadku 1 spočítajú. Inými slovami, názov stĺpca zostáva pre prvý výraz nezmenený (mal by sa naň uviesť absolútny odkaz) , ale číslo riadku sa zmení (je potrebné uviesť k nemu relatívny odkaz); druhý výraz mení číslo stĺpca (relatívna referencia), ale číslo riadku (absolútna referencia) zostáva nezmenené.
Zadajte do bunky B2 vzorec \u003d $ A2 + B $ 1 a skopírujte ho do celého rozsahu B2: J10. Mali by ste mať k dispozícii prídavný stôl, s ktorým bude oboznámený každý žiak prvého stupňa. 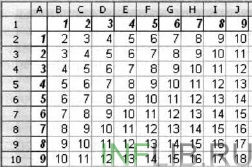
3.2.2. Zabudované funkcie
Pri spracovaní údajov v tabuľkách môžete využiť vstavané funkcie - preddefinované vzorce. Funkcia vráti výsledok vykonania akcií s hodnotami, ktoré fungujú ako argumenty. Používanie funkcií vám umožňuje zjednodušiť vzorce a sprehľadniť proces výpočtu.
Niekoľko stoviek vstavaných funkcií je implementovaných v tabuľkách, rozdelených na: matematické, štatistické, logické, textové, finančné atď.
Každá funkcia má jedinečný názov, ktorý sa používa na jej pomenovanie. Názov je zvyčajne skratka prirodzeného jazyka názvu funkcie. Pri vykonávaní tabuľkových výpočtov sa často používajú nasledujúce funkcie:
SUM (SUM) - súčet argumentov;
MIN (MIN) - určenie najmenšej hodnoty zo zoznamu argumentov;
MAX (MAX) - určiť najväčšiu hodnotu zo zoznamu argumentov.
Dialógové okno Sprievodca funkciami zjednodušuje vytváranie vzorcov a minimalizuje preklepy a chyby syntaxe. Keď zadáte funkciu do vzorca, v dialógovom okne Sprievodca funkciami sa zobrazí názov funkcie, všetky jej argumenty, popis funkcie a každého z argumentov, aktuálny výsledok funkcie a celý vzorec.
Príklad 4. Pravidlá rozhodcovského konania v medzinárodných súťažiach v jednom zo športov sú tieto:
1) výkonnosť každého športovca hodnotí N rozhodcov;
2) maximálna a minimálna známka (jedna, ak je ich viac) každého športovca sa zahodí;
3) pre športovca sa berie do úvahy aritmetický priemer zvyšných známok.
Informácie o súťaži sú uvedené v tabuľke: 
Je potrebné vypočítať známky všetkých účastníkov súťaže a určiť známku víťaza. Pre to:
1) do buniek A10, A1, A12 a A14 zadáme texty „Maximálna známka“, „Minimálna známka“, „Konečná známka“, „Skóre víťaza“;
2) do bunky B10 zadáme vzorec \u003d MAX (OT: B8); skopírujte obsah bunky B10 do buniek C10: F10;
3) do bunky V11 zadáme vzorec \u003d MIN (ВЗ: В8); skopírujte obsah bunky B10 do buniek C11: F11;
4) do bunky B12 zadáme vzorec \u003d (SUM (OT: B8) -B10-B11) / 4; skopírujte obsah bunky B12 do buniek C12: F12;
5) do bunky B14 zadáme vzorec \u003d MAKC (B12: F12).
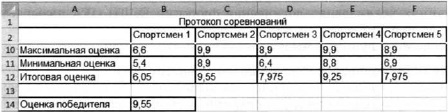
3.2.3. Logické funkcie
Pri štúdiu predchádzajúceho materiálu ste sa opakovane stretli s logickými operáciami NIE, AND, ALEBO (NIE, AND, ALEBO). Logické výrazy zostavené s ich pomocou ste použili pri organizovaní vyhľadávaní v databázach, pri programovaní rôznych výpočtových procesov.
Boolovské operácie sa implementujú aj do tabuliek, ale tu sa prezentujú ako funkcie: najskôr sa napíše názov logická operáciaa potom sú logické operandy uvedené v zátvorkách.
Napríklad logický výraz zodpovedajúci dvojnásobnej nerovnosti 0<А1<10, в электронных таблицах будет записано как И(А1>0; A1<10).
Pamätajte, ako sme napísali podobný logický výraz, keď sme sa oboznámili s databázami a programovacím jazykom Pascal.
Príklad 5. Vypočítajme v tabuľkách hodnoty logického výrazu NIE A A NIE B pre všetky možné hodnoty logických premenných, ktoré sú v ňom obsiahnuté. 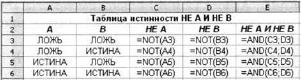
Pri riešení tohto problému sme postupovali podľa známeho algoritmu na zostrojenie pravdivostnej tabuľky pre logický výraz. Výpočty v rozmedzí buniek SZ: C6, D3: D6, EZ: E6 sa uskutočňujú počítačom podľa vzorcov, ktoré sme určili.
Na kontrolu podmienok pri výpočtoch v tabuľkových procesoroch je implementovaná logická funkcia IF nazývaná podmienená funkcia.
Podmienená funkcia má nasledujúcu štruktúru:
AK (<условие>; <действие1>; <действие2>)
Tu<условие> - Boolovský výraz, to znamená akýkoľvek výraz zostavený pomocou operácií a logických operácií, ktorý nadobúda hodnotu TRUE alebo FALSE.
Ak je boolovský výraz pravdivý, potom sa určí hodnota bunky, do ktorej je podmienená funkcia zapísaná<действие1>ak je nepravdivé -<действие2>.
Čo vám pripomína podmienenú funkciu?
Príklad 6. Zvážte problém prijatia do školského basketbalového tímu: do tohto tímu môže byť prijatý študent, ak je jeho výška najmenej 170 cm.
Údaje o uchádzačoch (priezvisko, výška) sú uvedené v tabuľke. 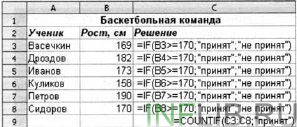
Použitie podmienenej funkcie v rozsahu buniek СЗ: С8 vám umožňuje urobiť rozhodnutie (prijaté / neprijaté) pre každého žiadateľa.
Funkcia COUNTIF vám umožňuje spočítať počet buniek v rozsahu, ktoré spĺňajú zadanú podmienku. Táto funkcia počíta počet uchádzačov vybraných pre tím v bunke C9.
písanie matematických vzorcov
Všeobecné vlastnosti a spustenie editora vzorcov
Písanie a úprava vzorcov v programe Word sa vykonáva pomocou editora vzorcov Microsoft Equation 3.0, ktorý obsahuje asi 120 šablón. Umožňuje vám vložiť do dokumentu matematické znaky a výrazy vrátane zlomkov, mocností, integrálov atď. Pri písaní vzorca sa automaticky použijú príslušné štýly pre jeho rôzne komponenty (zmenšená veľkosť písma pre exponenty, kurzíva pre premenné atď.).
Príklad. Spustenie editora vzorcov.
1. Umiestnite kurzor na miesto, kde zadáte, a upravte vzorec.
2. V ponuke Vložtenastav príkaz Objekt…, otvorte dialógové okno Vkladanie objektu.
3. Na karte Stvoreniev teréne Typ objektu:zvolme MicrosoftEquation3.0.
4. Kliknite na tlačidlo OK.
Otvorí sa dialógové okno pre prácu s editorom vzorcov.
Spustí sa editor vzorcov, ktorý upravuje existujúci vzorec dvojitým kliknutím do poľa vzorcov.
Dokončenie úpravy alebo napísania vzorca sa vykonáva mimo vstupného poľa pre vzorec.
Rozhranie editora vzorcov
Po spustení editora vzorcov sa otvorí okno editora vzorcov, ktoré má svoj vlastný panel nástrojov. Tento panel sa skladá z dvoch radov tlačidiel:
prístup k súborom znakov,
prístup k množinám šablón.
Do vzorca môžete z klávesnice zadávať písmená ruskej a latinskej abecedy, ako aj znaky najjednoduchších matematických operácií (+, -, /).
Riadok tlačidiel na prístup k znakovým sadám umožňuje zadávať do vzorca matematické symboly (operačné znaky a písmená gréckej abecedy).
Nasledujúce sady znakov sa nachádzajú v hornom riadku panela nástrojov zľava doprava:
• Symboly vzťahov;
Intervaly a bodky;
Matematické rozdiely;
Známky operácií;
symboly šípok;
• Symboly teórie množín;
Logické znaky;
Rôzne symboly;
grécke písmená.
Pomocou šablón panelov nástrojov môžete do vzorca vložiť znaky mnohých matematických operácií, nastaviť symboly integrálov, súčtov, výrobkov. Šablóny vám navyše umožňujú nastaviť formu matematického výrazu (zlomok, stupeň, index, matica atď.) Pre následné zadávanie matematických symbolov do obrobku získaného pomocou šablóny.
Nasledujúce sady šablón sa nachádzajú v spodnom riadku panela s nástrojmi zľava doprava:
Šablóny obmedzení;
Šablóny zlomkov a koreňov;
Vytváranie dolných a horných indexov;
integrály;
Podčiarknutie a podčiarknutie;
Značené šípky;
Práce a šablóny teórie množín;
Maticové šablóny.
Pri písaní znakov vzorca je kurzor vo forme znakov „alebo“. Znak zadaný do vzorca je umiestnený vpravo alebo vľavo od zvislej čiary a nad vodorovnou čiarou vstupného kurzora.
Písanie a úprava vzorcov
Pri písaní a úprave vzorca je možné zadať ďalší znak na jeho konci do hlavného vstupného riadku - miesto zadávaného znaku je automaticky označené medzerou (obdĺžnik s prerušovanou čiarou). Ak potrebujete zadať symbol pre súčet, integrál alebo inú zložitú štruktúru vzorca, pomocou myši vyberte príslušnú ikonu v príslušnej množine šablón.
Polotovary získané pomocou šablón je možné vložiť do stredu otvoru. Tak sa vytvárajú viacstupňové vzorce.
Úprava existujúceho vzorca zahŕňa odstránenie jeho jednotlivých prvkov a zadanie nových pomocou editora vzorcov.
Príklad. Písanie fragmentu vzorca.
Uveďme fragment vzorca v tvare: 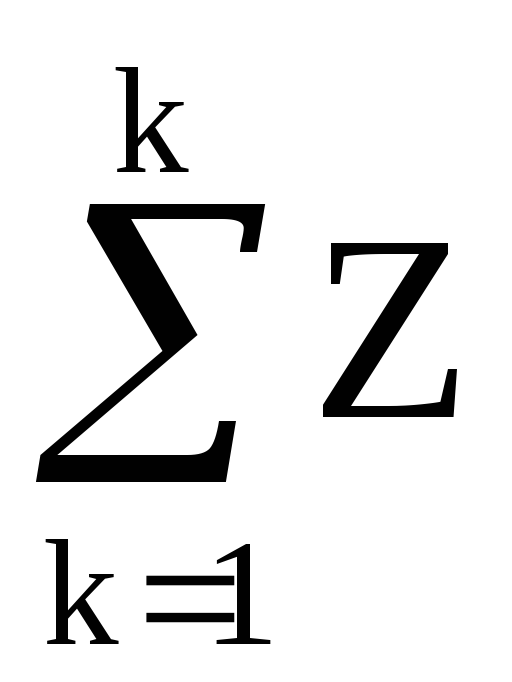 .
.
1. Kliknutím otvoríte podponuku so sadou šablón súčtov.
2. Kliknutím na myš vyberte šablónu súčtu s hornou a dolnou hranicou (v hornom riadku šablóna úplne vpravo).
Vo výsledku sa v okne úpravy vzorcov objaví prázdne miesto: .
3. Po vložení vstupného kurzora do každého zo slotov zadajte požadovaný symbol, číslo alebo výraz a fragment vzorca bude mať požadovanú formu.
Príklad. Odstránenie prvku vzorca.
1. Kliknutím na myš vyberte prvok, ktorý sa má vymazať.
2. Stlačte kláves
Ak je prvok vzorca súčasťou fragmentu vytvoreného pomocou šablóny, potom po jej odstránení vstupný priestor. Vstupný priestor je možné vymazať iba spolu so šablónou, ku ktorej patrí.
V niektorých prípadoch môže byť po odstránení prvkov vzorca grafické znázornenie niektorých jeho zvyšných prvkov narušené. Ak chcete vzorec vrátiť do pôvodného stavu, spustite príkaz Prekresliťponuka vyhliadka.
Príklad. Vkladanie nových položiek do vzorca.
1. Umiestnite kurzor na požadované miesto vo vzorci.
2. Predstavme požadovanú postupnosť symbolov.
3. Ak je to potrebné, pomocou šablóny vložte medzeru a potom vyplňte jej sloty potrebnými symbolmi.
Príklad. Písanie vzorca zlomkovou čiarou.
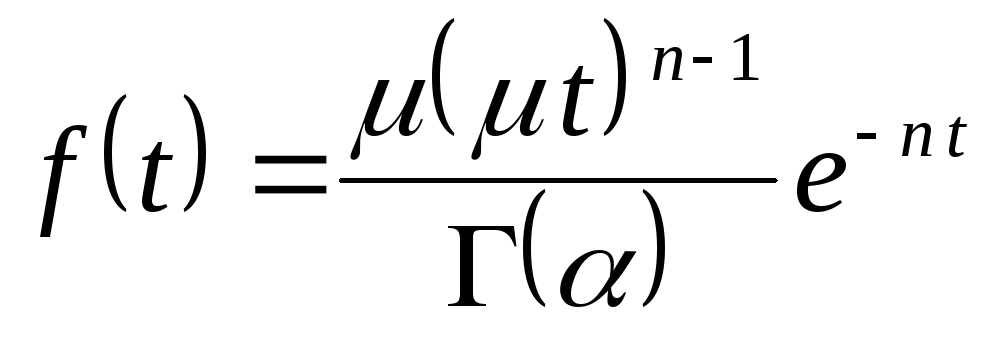 .
.
1. Umiestnite kurzor na miesto vzorca.
3. Do slotu na zadanie vzorca pomocou klávesnice zadajte začiatok vzorca "  ».
».
4. V súprave Frakcia a koreňové vzorcekliknite na šablónu
(šablóna vľavo hore).
Takto vložíte šablónu s dvoma slotmi do čitateľa a menovateľa zlomku.
5. Do slohu menovateľa zadajte výraz  , a v slote čitateľa -
, a v slote čitateľa - 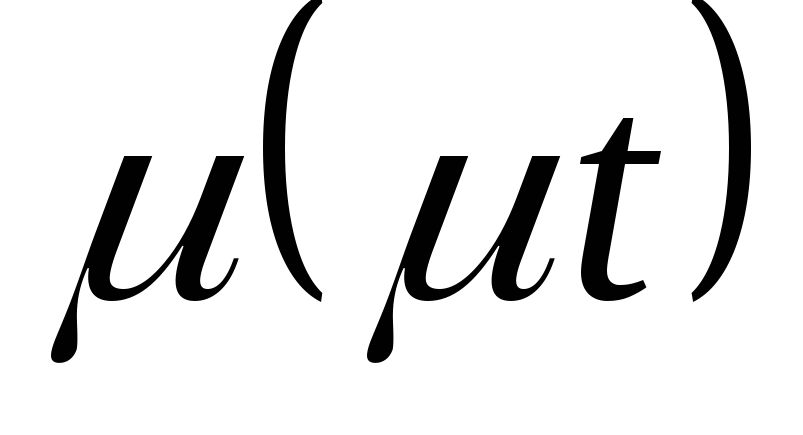 .
.
6. V sade šablón Vytváranie dolných a horných indexovvyberte šablónu, ktorá určuje vytvorenie indexu vpravo hore.
7. V zobrazenom slote zadajte výraz pre stupeň „n-1“.
8. Umiestnite kurzor na koniec už napísanej časti vzorca.
9. V sade šablón Vytváranie dolných a horných indexovvyberte šablónu.
10. Do zobrazeného poľa v hlavnom slote zadajte symbol „ e„, A do otvoru v pravom hornom indexe zadáme výraz stupňa“ - nt».
Kliknutím mimo rámca vzorca zatvorte dialógové okno úprav vzorca.
Písanie maticových vzorcov
Na zápis maticových vzorcov do spodného riadku panela s nástrojmi existuje sada Maticové šablóny.
Príklad. Písanie vzorca so zloženými zátvorkami.
Zvážte napísanie vzorca vo formulári: 
2. Otvorte okno editora vzorcov.
3. Do slotu na zadanie vzorca z klávesnice zadajte „ r= ».
4. V súprave Šablóny oddeľovačakliknite na šablónu.
Takto sa vloží kučeravá rovnátka so štrbinou napravo od nej.
5. Umiestnite kurzor do pomenovaného slotu.
6. V množine maticových šablón vyberte šablónu :.
Vo výsledku sa štrbina napravo od zloženej zátvorky prevedie na dva štrbiny umiestnené jeden nad druhým. To úmerne zvýši veľkosť samotnej kučeravej ortézy.
7. Do horného a dolného slotu zadajte príslušné výrazy vzorca.
8. Zatvorte dialógové okno na vytvorenie vzorca kliknutím myši.
Príklad. Písanie maticového vzorca.
Zvážte príklad zápisu vzorca pre determinant 3. rádu:
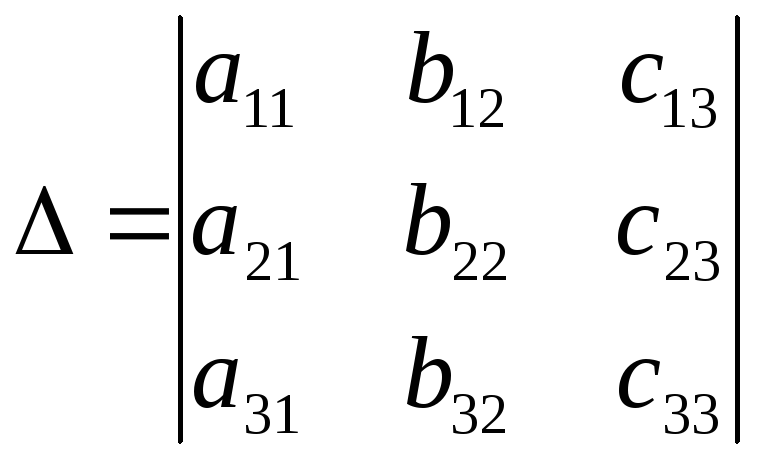 .
.
1. Umiestnite kurzor na miesto vzorca.
2. Otvorte okno editora vzorcov.
3. Do otvoru v ráme na zadanie vzorca z klávesnice zadajte „ \u003d“.
4. Otvorte súpravu Maticové šablónya vyberte šablónu:
5. Otvorí sa dialógové okno Matica... Nastavme počet riadkov a počet stĺpcov matice.
6. Kliknutím vľavo a napravo od maticového obrázka v okne nastavte zvislé čiary pozdĺž okrajov matice.
7. V skupine prepínačov Zarovnanie stĺpcavyberte prepínač Stred.
8. V skupine prepínačov Zarovnanie riadkov vyberte prepínač Na hlavnej linke... Kliknite na tlačidlo OK.
Takto vložíte prázdnu maticu s tromi riadkami a tromi stĺpcami a zvislými čiarami po stranách.
9. V prvom slote prvého riadku zadajte symbol „ a».
10. V množine šablón Vytvorte dolné a horné indexy vyberte šablónu, ktorá určuje vytvorenie indexu vpravo dole.
11. Zadajme do toho „11“.
12. Rovnakým spôsobom vyplňte zvyšok štrbín.
13. Kliknutím mimo rámček vzorca zatvorte dialógové okno na vytvorenie vzorca.

Zmeňte veľkosť a presuňte vzorec
Zmena veľkosti a presunutie vzorca sa vykonáva priamo v hlavnom okne dokumentu Word. Pred vykonaním ktorejkoľvek z týchto akcií musí byť vzorec vybraný kliknutím myši.
Príklad. Zmena veľkosti vzorca.
1. Vyberte vzorec kliknutím myši.
2. Umiestnite kurzor myši na jednu z ôsmich rukovätí výberového poľa a ťahajte ho, kým nezískate požadovanú veľkosť.
Ak neúmerne zmeníte veľkosť vzorca, môže dôjsť k narušeniu relatívnej polohy prvkov.
Ak chcete zmeniť mierku vzorca, vyberte vzorec a vyberte Upraviť | Objekt | Vzorec | Otvorené... Potom vyberte z ponuky príslušnú mierku (25% až 400%) vyhliadka.
Príklad. Posuňte vzorec.
1. Vyberte vzorec kliknutím myši.
2. Presuňte ukazovateľ myši nad vzorec tak, aby mal formu šípky smerovanej doľava.
3. Stlačte ľavé tlačidlo myši a ťahajte vzorec na požadované miesto v dokumente.
4. Ak chcete zmeniť vodorovnú polohu vzorca, nastavte príkaz Odstavec…ponuka Formáta pomocou vzorca nastavte požadované hodnoty parametrov odseku.
Toto je kapitola z knihy: Michael Girwin. Ctrl + Shift + Enter. Zvládnutie maticových vzorcov v programe Excel.
Tento príspevok je určený pre tých, ktorí sa skutočne zaujímajú o vzorce so zložitým poľom. Ak potrebujete zoznam jedinečných hodnôt načítať iba raz, je oveľa jednoduchšie použiť rozšírený filter alebo kontingenčnú tabuľku. Hlavnými výhodami používania vzorcov sú automatické aktualizácie pri zmene / pridaní zdrojových údajov alebo kritériách výberu. Pred čítaním je vhodné oprášiť myšlienky obsiahnuté v predchádzajúcich materiáloch:
- (kapitola 11);
- (kapitola 13);
- (kapitola 15);
- (kapitola 17).
Obrázok: 19.1. Získanie jedinečných záznamov pomocou možnosti Pokročilý filter
Stiahnite si poznámku vo formáte alebo príklady vo formáte
Načítanie jedinečného zoznamu z jedného stĺpca pomocou možnosti Pokročilý filter
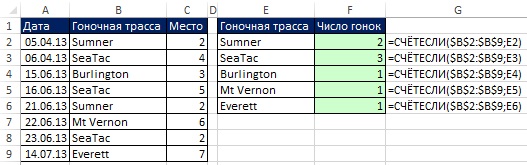
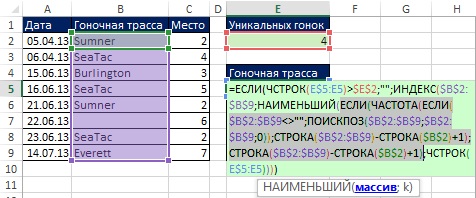
Na obr. 19.1 zobrazuje množinu údajov (rozsah A1: C9). Vaším cieľom je získať zoznam jedinečných závodných tratí. Pretože si potrebujete uchovať pôvodné údaje, nemôžete túto možnosť použiť Odstráňte duplikáty (Ponuka ÚDAJE –> Pracovať s údaje –> Odstráňte duplikáty). Ale môžete použiť Pokročilý filter... Otvorí sa dialógové okno Pokročilý filter, prechádzajte cez menu ÚDAJE –> Triediť a filtrovať –> Dodatočne, alebo stlačte a podržte kláves Alt a potom postupne stlačte klávesy S, L (pre program Excel 2007 alebo novší).
V otvorenom dialógovom okne Pokročilý filter (obr. 19.1) nastavte túto možnosť skopírujte výsledok na iné miesto, začiarknite políčko Iba jedinečné záznamy, zadajte oblasť, z ktorej sa budú získavať jedinečné hodnoty ($ B $ 1: $ B $ 9), a prvú bunku, do ktorej sa budú načítané údaje vkladať ($ E $ 1). Na obr. 19.2 zobrazuje výsledný jedinečný zoznam (rozsah E1: E6). Ak nezadáte názov poľa v Originálny rozsah dialógové okno Pokročilý filter (Namiesto použitia $ B $ 2: $ B $ 9 na obrázku 19.1) bude Excel považovať prvý riadok rozsahu za názov poľa a riskujete duplikát. Na obr. 19.3 zobrazuje jedno z mnohých možných použití jedinečného zoznamu.
![]()
Načítajte jedinečný zoznam na základe kritéria s možnosťou Pokročilý filter
V poslednom príklade ste získali jedinečný zoznam z jedného stĺpca. Pokročilý filter môže pomocou kritéria tiež načítať jedinečnú množinu záznamov (tj celý riadok pôvodnej tabuľky). Na obr. 19.4 a 19.5 zobrazujú situáciu, v ktorej chcete extrahovať jedinečné záznamy z rozsahu A1: D10, pre ktorý je názov spoločnosti ABC. Ďalej v tejto kapitole uvidíte, ako túto úlohu vykonať pomocou vzorca. Ak však nepotrebujete, aby bol proces automatický, môžete použiť Pokročilý filter, čo je určite jednoduchšie ako vzorec.
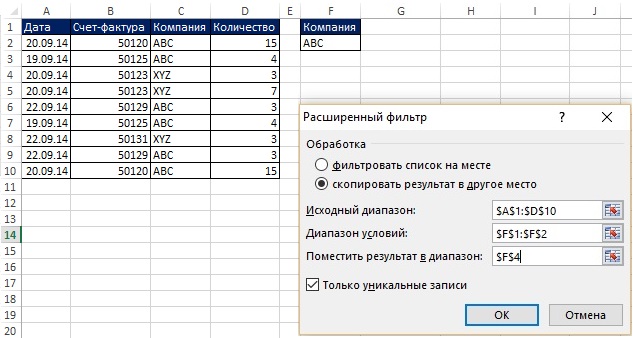
Obrázok: 19.4. Potrebujete jedinečné záznamy pre spoločnosť ABC; obrázok zväčšíte kliknutím naň pravým tlačidlom myši a výberom Otvoriť obrázok na novej karte

Obrázok: 19.5. Použitím Pokročilý filter získavanie jedinečných záznamov na základe kritérií je oveľa jednoduchšie ako pri metóde vzorca. Získané záznamy sa však nebudú automaticky aktualizovať, ak sa zmenia kritériá alebo zdrojové údaje.
Získanie jedinečného zoznamu z jedného stĺpca pomocou kontingenčnej tabuľky
Ak už používate kontingenčné tabuľky, viete to vždy, keď do oblasti vložíte ľubovoľné pole Struny alebo Stĺpce (Obrázok 19.6), automaticky získate jedinečný zoznam. Na obr. Obrázok 19.6 ukazuje, ako môžete rýchlo vytvoriť jedinečný zoznam závodných dráh a potom spočítať počet návštev na každej z nich. Aj keď je kontingenčná tabuľka užitočná na načítanie jedinečného zoznamu z jedného stĺpca, je nepravdepodobné, že by bola užitočná na načítanie jedinečných záznamov na základe kritérií.
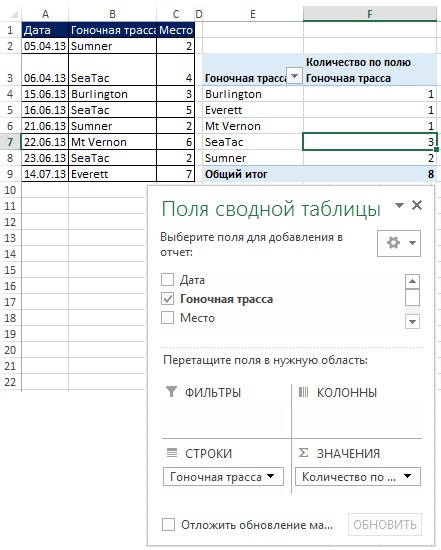
Obrázok: 19.6. Môžeš použiť súhrnná tabuľkakeď potrebujete jedinečný zoznam a na základe neho následný výpočet
Extrahujte jedinečný zoznam z jedného stĺpca pomocou vzorcov a pomocného stĺpca
Použitie pomocného stĺpca uľahčuje načítanie jedinečných údajov ako použitie maticových vzorcov (obrázok 19.7). Tento príklad používa techniky, ktoré ste sa naučili (pomocou funkcie COUNTIF) a (pomocou pomocného stĺpca). Ak teraz zmeníte pôvodné údaje v rozsahu B2: B9, vzorce budú automaticky odrážať tieto zmeny v oblasti D15: D21.

Pole vzorec: Pomocou funkcie MALÝ extrahujte jedinečný zoznam z jedného stĺpca
Pretože maticové vzorce použité v tejto časti sú veľmi zložité na pochopenie, ich tvorba je rozdelená do etáp: prvý je fragment, ktorý počíta jedinečné hodnoty (kapitola 17); druhým je extrakcia údajov na základe kritérií (kapitola 15). Na obr. Obrázok 19.8 zobrazuje vzorec na výpočet jedinečných hodnôt (keďže ide o maticový vzorec, môžete ho zadať stlačením klávesov Ctrl + Shift + Enter). Všimnite si nasledujúce aspekty tohto vzorca:
- Funkcia FREQUENCY vráti pole čísel (obr. 19.9): pri prvom objavení sa závodnej trate sa vráti počet jej výskytov v pôvodných dátach; pri každom ďalšom výskyte závodnej dráhy sa vráti nula (pozri). Napríklad Sumner sa objaví na prvej a piatej pozícii v poli. Na prvej pozícii funkcia FREQUENCY vráti 2 - celkový počet letných v rozsahu B2: B9, na piatej pozícii - 0.
- V argumente sa nachádza funkcia FREQUENCY log_expression funkcia IF, takže funkcia IF vráti TRUE pre každú nenulovú hodnotu a FALSE pre každú nenulovú hodnotu.
- Argument hodnota_ak_pravda funkcie IF obsahuje 1, takže funkcia SUM počíta také množstvo.
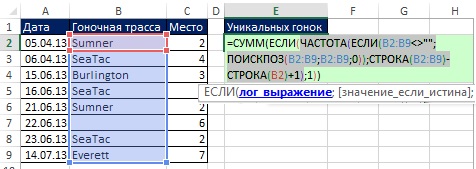
Obrázok: 19.8. V argumente sa nachádza funkcia FREQUENCY log_expression funkcie IF
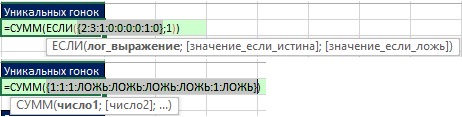
Obrázok: 19.9. (1) funkcia FREQUENCY vráti pole čísel; (2) funkcia IF vráti 1 pre nenulové čísla a FALSE pre nuly
Teraz vytvorme vzorec na získanie jedinečného zoznamu. Na obr. 19.10 ukazuje pole relatívnych polôh umiestnených v argumente pole funkcie MALÉ.
V predchádzajúcom príklade (obr. 19.9) v argumente hodnota_ak_pravda funkcia IF mala jeden pridelený, takže funkcia IF vrátila jeden a FALSE. Tu (obr. 19.10) argument hodnota_ak_pravda obsahuje: LINE ($ B $ 2: $ B $ 9) -LINE ($ B $ 2) +1. Preto funkcia IF (vo vnútri funkcie MALÉ) vráti relatívne číslo pozície v rozsahu s jedinečnou závodnou dráhou alebo FALSE pre take (obrázok 19.11).
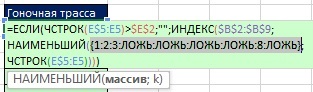
Obrázok: 19.11. Funkcia IF vráti relatívne číslo pozície v rozsahu s jedinečnou závodnou dráhou, alebo FALSE pre take
Na obr. 19.12 ukazujú výsledky vzorca. Na obr. 19.13 ukazuje, že akonáhle sa pôvodné údaje zmenili, vzorce tieto zmeny okamžite zohľadnili. Ale čo keď pridáte nové záznamy? Ďalej uvidíte, ako vytvoriť vzorce pre dynamický rozsah.
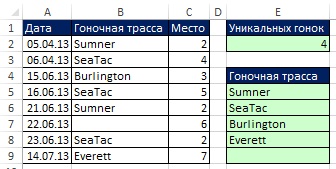
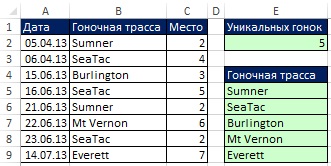
Obrázok: 19.13. Ak sa pôvodné údaje zmenia, vzorec sa okamžite aktualizuje. Filtre a Pokročilý filter sa nemôžu aktualizovať automaticky bez napísania kódu VBA
Vzorec poľa: Extrahujte jedinečný zoznam z jedného stĺpca pomocou dynamického rozsahu
Pridajme posledný príklad podľa toho, čo ste sa dozvedeli o vzorcoch používajúcich konkrétne názvy založené na dynamickom rozsahu (). Na obr. 19.14 je vzorec na určenie mena Sledovať... Tento vzorec predpokladá, že za riadkom 51 nikdy nezadáte záznam.
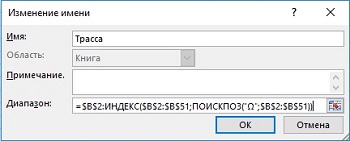
Obrázok: 19.14. Definícia mena Sledovať na základe vzorca
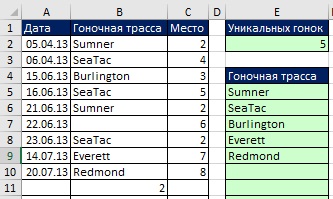
Po identifikácii názvu ho môžete použiť v ľubovoľnom vzorci. Na obr. Obrázok 19.15 zobrazuje spôsob použitia názvu na spočítanie počtu jedinečných hodnôt (porovnajte s obrázkom 19.8). A na obr. 19.16 ukazuje vzorec, ktorý extrahuje samotné jedinečné hodnoty zo zoznamu závodných dráh. Upozorňujeme, že namiesto úryvku rozsah<>„“ (Ako to bolo na obr. 19.8 a 19.10), použije sa funkcia ETEXT (akýkoľvek text vráti hodnotu PRAVDA). Ak v prípade použitia ETEXTu zadáte číslo (ako v bunke B11) alebo akýkoľvek iný netextový text, bude vzorec túto hodnotu ignorovať. Na obr. 19.17 ukazuje, že vzorec automaticky extrahuje všetky nové názvy sledovaní a ignoruje čísla.

![]()
Obrázok: 19.16. Načítanie jedinečného názvu zarovnania na základe dynamického rozsahu
Vytvorte vzorec jedinečných hodnôt pre rozbaľovací zoznam
Na základe práve skontrolovaného príkladu definujte druhé meno - TrackList, tiež založené na dynamickom rozsahu, ale teraz odkazujúce na zoznam jedinečných stôp (rozsah E5: E14, obrázok 19.18). Pretože rozsah E5: E14 obsahuje iba text a prázdne hodnoty (testovacie reťazce s nulovou dĺžkou - „“), v argumente vyhľadávacia_hodnota funkcia MATCH môže používať zástupné znaky *? (čo znamená aspoň jeden znak). A v hádke typ_zhody funkcia MATCH by mala použiť hodnotu –1 na nájdenie posledného textového prvku v stĺpci, ktorý obsahuje aspoň jeden znak. Ako je znázornené na obr. 19.18, potom môžete v poli použiť konkrétny názov Zdroj okno Validácia vstupných hodnôt (podrobnosti o vytváraní rozbaľovacieho zoznamu nájdete na). Rozbaľovací zoznam sa môže rozširovať a zmršťovať pri pridávaní alebo odstraňovaní nových údajov v stĺpci B.

Kde sa so zástupnými znakmi má zaobchádzať ako s bežnými znakmi
Ako ste sa dozvedeli v, niekedy musia byť zástupné znaky považované za znaky. Na obr. 19.18 ukazuje, ako môžete v týchto prípadoch zmeniť vzorce. Pred rozsah argumentov pripojíte vlnovku vyhľadávacia_hodnota Funkcia SEARCH a na koniec rozsahu v argumente pripojte prázdny reťazec lookup_array.
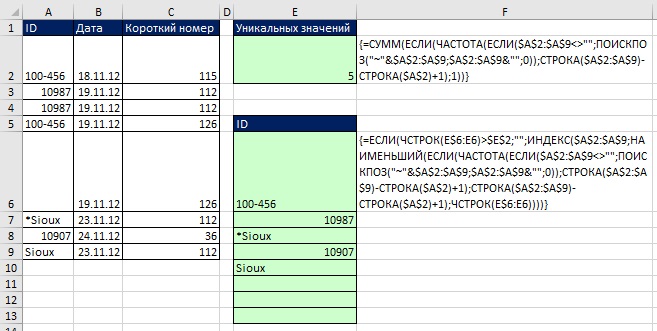
Použitie pomocného stĺpca alebo maticového vzorca na získanie jedinečných záznamov na základe kritérií
Na začiatku tohto príspevku sa ukázalo, že na získanie jedinečných záznamov na základe kritérií to funguje vynikajúco Pokročilý filter... Ak však potrebujete okamžitú aktualizáciu, môžete použiť stĺpec pomocníka (obrázok 19.20) alebo maticové vzorce (obrázok 19.21).

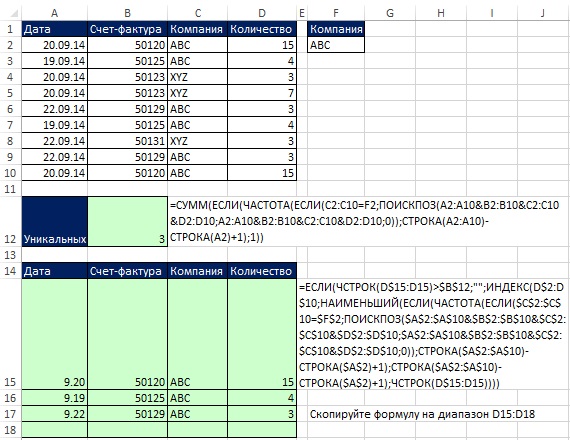
Dynamické vzorce na extrahovanie mien a predaja zákazníkov
Vzorce sú znázornené na obr. 19,22. Napríklad ak pridáte nový záznam TTNákladné autá na riadku 17 , vzorec SUMIF v bunke F15 automaticky pridá novú hodnotu. Ak do stĺpca B pridáte nového zákazníka, okamžite sa objaví v stĺpci E a vzorec SUMIF v stĺpci F zobrazí nový súčet.

Obrázok: 19,22. Použitie konkrétneho názvu a dvoch vzorcov poľa na získanie jedinečných zákazníkov a objemu predaja
Všimnite si, že funkcia SUMIF v argumente sum_rangeobsahuje jednu bunku - $ C $ 10. Tu je to, čo k tejto téme môže pomôcť vzorec SUMIF: argument sum_range nemusí mať rovnakú veľkosť ako argument rozsah... Ľavá horná bunka argumentu sa používa ako počiatočná bunka pri určovaní skutočných buniek, ktoré sa majú pridať sum_range, a potom sa sčítajú bunky časti rozsahu, ktorá zodpovedá veľkosti argumentu rozsah... Vzorce zadané do buniek E15 a F15 sa kopírujú pozdĺž stĺpcov.
Triedenie číselných hodnôt
Vzorce na triedenie čísel sú dosť jednoduché, ale na triedenie zmiešaných údajov sú šialene zložité. Ak teda nepotrebujete okamžitú aktualizáciu, je lepšie zaobísť sa bez vzorcov pomocou tejto možnosti Triedenie... Na obr. 19.23 sú zobrazené dva vzorce triedenia.
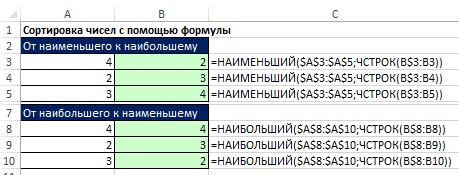
Na obr. 19.24 ukazuje, ako môžete pomocou stĺpca pomocníka triediť čísla. Pretože funkcia RANK netriedi rovnaké čísla (dáva im rovnaké poradie), na ich rozlíšenie bola pridaná funkcia COUNTIF. Upozorňujeme, že funkcia COUNTIF má rozšírený rozsah, ktorý začína o jednu líniu vyššie. Je to nevyhnutné, aby prvé uvedenie ľubovoľného čísla neprispievalo. Druhým výskytom čísla sa poradie zvýši o jednu. Toto postupné číslovanie nastavuje poradie, v akom funkcie INDEX a SEARCH načítajú záznamy v rozsahu A8: B12.
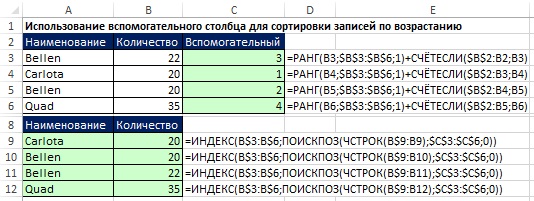
Ak si môžete dovoliť vytvoriť pomocný stĺpec v oblasti extrakcie dát (rozsah A10: A14 na obrázku 19.25), je vhodné použiť vyššie popísané triedenie čísel na základe funkcie SMALL a na základe nej extrahovať mená pomocou funkcie poľa.

Obrázok: 19,25. Ak nemôžete použiť pomocný stĺpec, použite MALÉ triedenie (v bunke A11) a maticový vzorec (v bunke B11)
V podnikaní a športe je často potrebné vyťažiť N najlepších hodnôt a názvy spojené s týmito hodnotami. Riešenie začnite vzorcom COUNTIF (bunka A11 na obrázku 19.26), ktorý určí počet záznamov, ktoré sa majú zobraziť. Všimnite si, že argument kritérium vo funkcii COUNTIF v bunke A11 - viac alebo rovnaké hodnota v bunke D8. Toto umožňuje zobrazenie všetkých hraničných hodnôt (v našom príklade, aj keď chceme zobraziť Top 3, existujú štyri vhodné hodnoty).
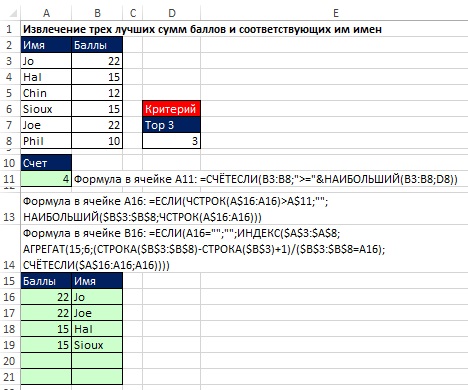
Obrázok: 19,26. Získanie prvých troch skóre a ich zodpovedajúcich mien. Keď sa N zmení v bunke D8, oblasť A15: B21 sa aktualizuje
Triedenie textových hodnôt
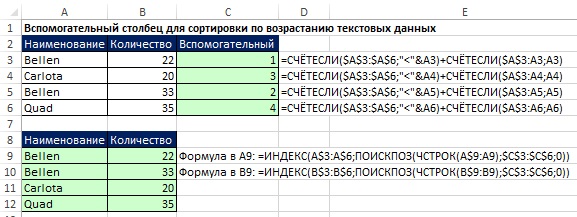
Ak môžete použiť pomocný stĺpec, úloha nie je taká náročná (obrázok 19.27). Porovnávacie operátory spracúvajú textové znaky na základe číselných kódov ASCII priradených znakom. V bunke C3 prvá funkcia COUNTIF vráti nulu a druhá pridá jednu. V C4: 2 + 1, C5: 0 + 2, C6: 3 + 1.
Triedenie zmiešaných údajov
Vzorec, ktorý umožňuje extrahovať jedinečné hodnoty zo zmiešaných údajov a potom ich triediť, je veľmi veľký (obrázok 19.28). Pri jeho tvorbe boli použité nápady, s ktorými sa v tejto knihe stretávame už skôr. Začnime skúmať vzorec tým, že sa pozrieme na to, ako funguje štandardná funkcia triedenia v programe Excel.

Excel triedi výsledky v nasledujúcom poradí: najskôr čísla, potom text (vrátane reťazcov s nulovou dĺžkou), FALSE, TRUE, chybové hodnoty v poradí, v akom sa zobrazujú, prázdne bunky. Všetko triedenie prebieha v súlade s kódmi ASCII. Existuje 255 kódov ASCII, z ktorých každý zodpovedá číslu od 1 do 255:
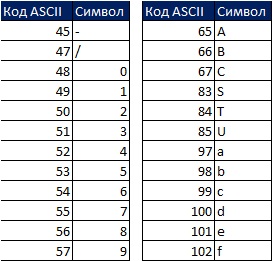
Napríklad 5 je ASCII 53 a S je ASCII 83. Ak zoradíte dve hodnoty, 5 a S, od najnižšej po najvyššiu, potom 5 je vyššia ako S, pretože 53 je menej ako 83.
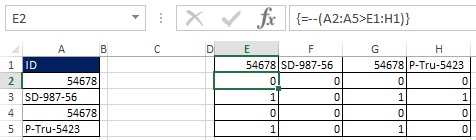
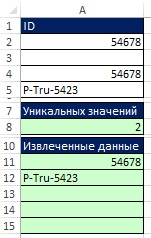
Súbor údajov v rozsahu A2: A5 (obr. 29) sa prevedie na rozsah E2: E5 v súlade s pravidlami triedenia. Pre lepšie pochopenie princípov triedenia zvážte hodnoty v rozmedzí C2: C5. Napríklad, ak si položíte otázku „Koľko nado mnou v poradí?“ na ID v bunke A2 (54678) bude odpoveď nulová, pretože v zoradenom zozname bude ID 54678 najvyšší. SD-987-56 bude mať nad sebou tri ID. Potrebujete vzorec na získanie hodnôt v rozsahu C2: C5.

Najskôr vyberte rozsah E1: H1 a do riadku vzorcov zadajte \u003d TRANSPOSE (A2: A5), zadajte vzorec stlačením Ctrl + Shift + Enter (obr. 19.30). Ďalej na paneli vzorcov vyberte rozsah E2: H5, zadajte \u003d A2: A5\u003e E1: H1 a zadajte vzorec stlačením Ctrl + Shift + Enter (obr. 19.31). Na obr. Obrázok 19.32 zobrazuje výsledok ako obdĺžnikové pole hodnôt TRUE a FALSE, ktoré zodpovedajú každej z buniek vo výslednom poli, ako odpoveď na otázku „Je nadpis riadku väčší ako nadpis stĺpca?“
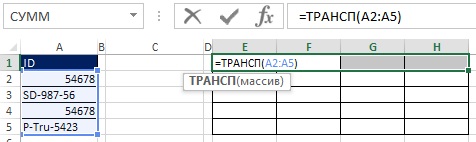
Obrázok: 19.30. Vyberte rozsah E1: H1 a zadajte maticové vzorce

Obrázok: 19,31. V rozsahu E2: H5 zadajte vzorec poľa \u003d A2: A5\u003e E1: H1

Obrázok: 19,32. Každá bunka z rozsahu E2: H5 obsahuje odpoveď na otázku „Je hlavička riadku väčšia ako hlavička stĺpca?“
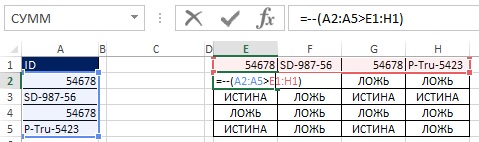
Napríklad bunka E3 kladie otázku: SD-987-56\u003e 54678. Pretože 54678 je menej ako SD-987-56, odpoveď je PRAVDA. Upozorňujeme, že rozsah E3: H3 obsahuje tri TRUE a jednu FALSE hodnoty. Pri pohľade späť na obr. 19.29, môžete vidieť, že číslo tri je v bunke C3.
Ako je znázornené na obrázkoch 19.33 a 19.34, hodnoty TRUE a FALSE môžete previesť na jednotky a nuly pridaním dvojitých negatívov do vzorca poľa. Pretože pôvodné pole (E2: H5) má rozmer 4 × 4 a chcete výsledok v podobe poľa 4 × 1, použite funkciu MULTIFUNKCIA (pozri obr. 19.35 a). Funkcia MULTIPLE je funkcia poľa, zadajte ju teda stlačením klávesov Ctrl + Shift + Enter (Obrázok 19.36). Teraz namiesto použitia rozsahu E2: H5 pridajte príslušné prvky do vzorca (Obrázok 19.37).

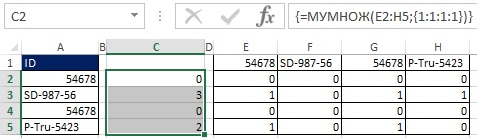
Obrázok: 19,36. Výberom rozsahu C2: C5 a zadaním funkcie poľa MULTIPLE získate stĺpec čísel, ktoré hovoria, koľko ID je v zoradenom zozname nad vybraným.
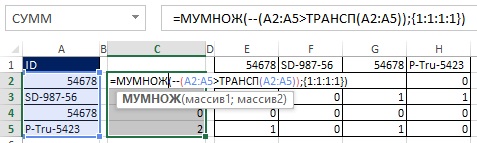
Obrázok: 19,37. Namiesto použitia pomocného rozsahu E2: H5 sú do vzorca pridané zodpovedajúce prvky
Na obr. 19.38 ukazuje, ako môžete nahradiť pole konštánt reťazcom STRING ($ A $ 2: $ A $ 5) ^ 0.
Obrázok: 19,39. Na riešenie potenciálnych prázdnych buniek by mali byť všetky výskyty A2: A5 doplnené IF (A2: A5<>„“, A2: A5); funkcia STRING takéto doplnenie nevyžaduje, pretože funkcia pracuje s adresou bunky, nie s jej obsahom
Pretože konečný vzorec sa použije inde, musíte urobiť všetky rozsahy absolútnymi (obrázok 19.40). Na obr. 19.41 zobrazuje výsledné hodnoty.
Obrázok: 19.40. Rozsahy A2: A5 sa zmenili na absolútne hodnoty
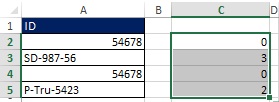
Pretože sa tento prvok v budúcnosti bude používať dvakrát, môžete ho uložiť pod konkrétnym názvom. Ako je zobrazené v dialógovom okne (obr. 19.42), vzorec má názov SZB - Koľko je viac hodnôt.
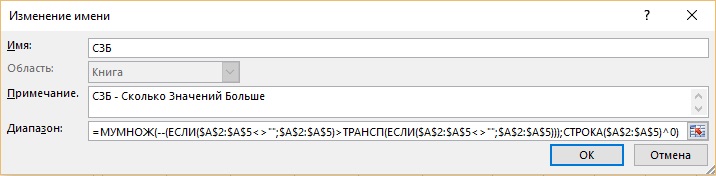
- Argument pole funkcia INDEX sa vzťahuje na pôvodný rozsah A2: A5.
- Prvá funkcia MATCH povie funkcii INDEX relatívnu polohu prvku v poli A2: A5.
- Zatiaľ čo argument vyhľadávacia_hodnota funkcia SEARCH zostane prázdna.
- Zadaný názov (SZB) v argumente lookup_array vám umožní prvý prístup k prvku, ktorý má hodnotu 0, potom 2 a nakoniec 3.
- Nula v argumentácii typ_zhody určuje presnú zhodu, ktorá eliminuje odkaz na duplikáty.

Obrázok: 19,43. Spustíte vzorec na extrahovanie a triedenie údajov v bunke A11. Argument vyhľadávacia_hodnota funkcia SEARCH zatiaľ zostáva prázdna
Predtým, ako vytvoríte argument vyhľadávacia_hodnota funkcia HĽADAŤ, pamätajte, čo vlastne potrebujete. Existujú tri jedinečné ID, ktoré je potrebné zoradiť, takže v argumente potrebujete tri čísla vyhľadávacia_hodnota ako je vzorec kopírovaný nadol. Tieto čísla vám umožnia nájsť relatívnu pozíciu v poli A2: A5, ktorú musíte poskytnúť funkcii INDEX:
- V bunke A11 funkcia MATCH vráti 0, čo zodpovedá relatívnej polohe 1 v rámci zadaného názvu MSB.
- Keď je vzorec skopírovaný nadol do bunky A12, funkcia MATCH by mala vrátiť číslo 2 a relatívnu pozíciu \u003d 4 vo vnútri MSB.
- V bunke A13 by funkcia MATCH mala vrátiť hodnotu 3 a relatívna poloha \u003d 2 v rámci MSB.
Obraz sa objaví, keď sa zamyslíte nad tým, o čom je argument vyhľadávacia_hodnota pri kopírovaní vzorca nadol sa musí dopyt zhodovať: „Zadajte minimálnu hodnotu v rámci konkrétneho názvu SZB, ktorý sa ešte nepoužil.“ Ako je znázornené na obr. 19,44 prvok vzorca MIN (IF (UND (SEARCH ($ A $ 2: $ A $ 5; A $ 10: A10; 0)); SZB)) vráti minimálnu hodnotu pri kopírovaní vzorca nadol a presne odpovedá na dotaz. Dôvod, prečo to funguje, je ten, že vo fragmente UNM (SEARCH ($ A $ 2: $ A $ 5; A $ 10: A10; 0)) sa porovnávajú dva zoznamy (pozri). Všimnite si rozširujúci sa rozsah A $ 10: A10 v argumente lookup_array... V bunke A11 kombinácia UND a MATCH pomáha extrahovať všetky jedinečné čísla z MSB a poskytnúť ich funkcii MIN. Keď skopírujete vzorec do bunky A12, ID extrahované v bunke A11 sa opäť nachádza v rozšírenom rozsahu a bude opäť nájdené v rozsahu $ A $ 2: $ A $ 5. UND však vráti FALSE a z MWB sa nezíska nijaká hodnota. Ak to chcete vidieť, zadajte vzorec poľa na obrázku 19.44 stlačením klávesov Ctrl + Shift + Enter a skopírujte ho nadol.
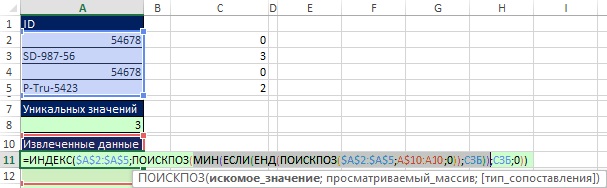
Obrázok: 19,44. Element vzorca v argumente vyhľadávacia_hodnota funkcia MATCH sa zhoduje s dotazom: "Zadajte minimálnu hodnotu v rámci konkrétneho názvu SZB, ktorý ešte nebol použitý"
Na obr. 19.45 ukazuje, že argument lookup_array druhá funkcia VYHĽADÁVAŤ rozsah A $ 10: A10 sa rozšíril na A $ 10: A11. Aby ste pochopili, ako tento vzorec funguje, postupne vyberte jeho fragmenty a kliknite na F9 (obr. 19.46-19.49).
Obrázok: 19,45. Rozšíriteľný rozsah A $ 10: A11 teraz (v bunke A12) obsahuje prvé ID (54678)
Obrázok: 19,46. Kombinácia funkcií UND a druhej funkcie SEARCH poskytuje celý rad boolovských hodnôt; dve FALSE hodnoty vylučujú nulové hodnoty z konkrétneho názvu MSB
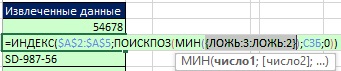
Obrázok: 19,47. Nuly sú vylúčené a zostávajú iba čísla 3 a 2; číslo 2 je minimum, takže práve toto by sa malo extrahovať nasledovne
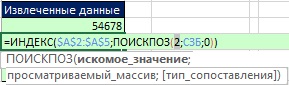
Obrázok: 19,48. Funkcia MIN vyberie číslo 2; teraz funkcia MATCH môže nájsť správnu relatívnu polohu pre funkciu INDEX

Obrázok: 19,49. Funkcia INDEX načíta hodnotu 2, ktorá zodpovedá relatívnej štvrtej pozícii ID v rozsahu A2: A5
Po návrate do bunky A11 teraz môžete pridať ďalšiu podmienku, aby prázdne bunky neovplyvnili vzorec (obrázok 19.50).
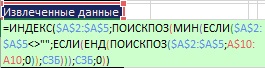
Obrázok: 19,50. Vo vnútri funkcie MIN existujú dve podmienky; prvý: „bunky nie sú prázdne?“, druhý: „hodnota ešte nebola použitá?“
Na obr. Konečný vzorec je 19,51. Bola pridaná podmienka, aby riadky v rozsahu A11: A15 zostali po načítaní zoradených jedinečných hodnôt prázdne. Na obr. 19.52 ukazuje, čo sa stane, ak je bunka A3 prázdna. Náš doplnok na kontrolu prázdnych buniek fungoval.
Nebolo to ľahké. Ale ak ste sa dočítali až sem, dúfam, že sa vám páčili.
VÝPOČTY V ELEKTRONICKÝCH TABUĽKÁCH
2.1. V o d f o r m u l s
Výpočet hodnoty bunky sa vykonáva zadaním vzorca. Vzorce vždy začínajú znakom rovnosti „ = ”.
Vzorce umožňujú vykonávať bežné matematické operácie s hodnotami z buniek v hárku. Napríklad musíte pridať hodnoty do buniek B1 a B2 a zobraziť ich súčet v bunke B5. Umiestnite kurzor do bunky B5 a zadajte vzorec „\u003d B1 + B2“.
Zadanie vzorca sa objaví v bunke tabuľky aj na paneli vzorcov. Po stlačení tlačidla Zadajte vykonajú sa výpočty a výsledok sa získa v aktívnej bunke.
Vo vzorcoch je možné použiť nasledujúce operátory:
a r i f m e t i c e -
w a n i -
t e c t a -
|
& - zreťazenie textových hodnôt. |
Pri výpočte vzorca v tabuľke sa použije aritmetické poradie operácií.
2.2. TVORBA FORMULÁROV S VEĽKOU
Môžete zadať súradnice buniek do vzorca nasmerovaním kurzora na požadovanú bunku. Pri manuálnom zadávaní vzorca existuje riziko chyby. Tomu sa dá vyhnúť nasledujúcim spôsobom:
umiestnite kurzor do bunky, do ktorej chcete zadať vzorec;
zadajte rovnaké znamienko „\u003d“;
umiestnite kurzor do bunky, ktorej súradnice by mali byť na začiatku vzorca, a kliknite na tlačidlo myši;
zadajte operátor (napríklad znamienko „+“) alebo iný znak, ktorý pokračuje vo vzorci;
presuňte kurzor na bunku, ktorej súradnice chcete použiť vo vzorci, a kliknite na tlačidlo myši;
vykonávať tieto činnosti, kým sa vzorec neskončí.
2.3. A b s o lutna a asi s a t e l n e c e c
Existujú tri hlavné typy adries (odkazov): relatívna, absolútna a zmiešaná.
Rozdiely medzi relatívnymi a absolútnymi odkazmi sa objavia, keď kopírujete a presúvate vzorce z jednej bunky do druhej.
Pri premiestňovaní alebo kopírovaní sa absolútne odkazy vo vzorcoch nezmenia a relatívne odkazy sa automaticky aktualizujú na základe novej polohy.
Napríklad bunka A1 obsahuje konštantu 4, bunky B1 až B10 obsahujú hodnoty od 0,1 do 1 v prírastkoch 0,1. Ak chcete získať výsledok v bunkách D1: D10 podľa vzorca 4b i, kde i \u003d 1, 2, ..., 10, musíte napísať do bunky D1 „\u003d $ A $ 1 * B1“ a skopírovať vzorec do bunky D2, D3, ..., D10. V takom prípade bude D2 obsahovať frázu „$ A $ 1 * B2“, v D3 - „$ A $ 1 * B3“ atď., Kde sa obsah $ A $ 1 nezmení, pretože adresa (odkaz ) je absolútna a B1 sa zmení na B2, B3, ..., B10, pretože adresa je relatívna.
Na označenie rozsahu buniek vo vzorcoch použite symbol „ : ”, Napríklad: A2 : A5.
Na označenie skupiny nesusediacich buniek použite symbol „ ; ”, Napríklad: A2; B5; E10.
2.4. VZOROVÁ ÚPRAVA
Vzorce sa upravujú rovnakým spôsobom ako obsah buniek.
najprvth cesta... Musíte zvoliť požadovanú bunku, kliknúť na lištu vzorcov a upraviť ju.
Druhá cesta... Dvakrát kliknite na bunku a upravte vzorec priamo v bunke.
2.5. A pomocou funkcie
Jednou z najužitočnejších funkcií programu EXCEL je jeho široká škála funkcií, ktoré vám umožňujú vykonávať rôzne typy výpočtov. Každá funkcia má syntax pre zápis:
NÁZOV FUNKCIE (argument 1; argument 2; ...).
Argumentmi funkcií môžu byť čísla, texty, logické hodnoty, chybové hodnoty, odkazy, polia. V desatinných číslach je celočíselná časť oddelená od zlomkového znaku „,“ napríklad: –30,003.
Textové hodnoty musia byť uzavreté v úvodzovkách. Ak samotný text obsahuje úvodzovky, mali by sa zdvojnásobiť.
Boolovské hodnoty sú TRUE a FALSE. Logickými argumentmi môžu byť tiež porovnávacie výrazy, pre ktoré je možné vyhodnotiť TRUE alebo FALSE, napríklad: B10\u003e 20.
Napríklad funkcia AVERAGE počíta aritmetický priemer zo série hodnôt. Výraz „\u003d PRIEMERNÝ (6; 12; 15; 16)“ dá výsledku 12,75. Ak sú hodnoty 6, 12, 15, 16 uložené v bunkách B10 - B15, potom je možné vzorec zapísať takto: „\u003d PRIEMERNÝ (B10: B15)“.
Funkcia SUM sa používa na určenie súčtu hodnôt, napríklad: „\u003d SUM (B10: B15)“. Sčítajú sa čísla 6, 12, 15, 16.
Je vhodné zaviesť funkciu do vzorca pomocou Sprievodcovia funkciami ... Sprievodca funkciami vám umožňuje zadať funkciu do vzorca, ktorý vytvárate. Postupujte takto:
umiestnite kurzor do bunky, kde chcete zadať funkciu;
na štandardnom paneli nástrojov kliknite na tlačidlo sprievodcu funkciami ¦ X alebo vykonajte príkaz Funkcia Vložiť + ;
v dialógovom okne, ktoré sa zobrazí v zozname Kategórie vyberte požadovanú kategóriu funkcií. Potom v zozname Funkcia zobrazia sa funkcie vybranej kategórie;
v zozname Funkcia vyberte funkciu a kliknite na tlačidlo Ok ;
zobrazí sa dialógové okno v závislosti od typu vybranej funkcie;
zadajte požadované hodnoty alebo rozsahy buniek pre argumenty funkcie;
kliknite na tlačidlo v dialógovom okne Ok .
2.6. Auto matic s u m i r o v a e
Najjednoduchšou metódou na sčítanie tabuľky je automatické sčítanie. Umiestnite kurzor do bunky pod stĺpcom alebo napravo od riadku, ktorého hodnoty je potrebné sčítať, a kliknite na tlačidlo na štandardnom paneli nástrojov. Automatický súčet (zobrazuje symbol „ å “). Potom stlačte tlačidlo Zadajte .
Pri sčítaní prvkov matice podľa stĺpcov a riadkov je vhodné vybrať bunky matice s ďalším riadkom a stĺpcom a potom stlačiť tlačidlo „ å “. Automaticky sa získa súčet všetkých riadkov a stĺpcov matice.
2.7. Č asto pre prácu s m a s i in a m i
Pole vzorcov (tabuľkové vzorce) vám umožňuje vykonať veľa výpočtov napísaním jedného vzorca. Napríklad musíte vynásobiť hodnoty v stĺpci A2: A6 zodpovedajúcimi B2: B6. Výsledok zaznamenajte do formátu C2: C6 bez kopírovania vzorca.
Musíte urobiť nasledovné:
vyberte bunky výsledku C2: C6;
zadajte znak „\u003d“;
vyberte bunky A2: A6;
zadajte znak „*“;
zvýrazniť B2: B6;
stlačte klávesy na klávesnici Shift + Ctrl + Enter .
Vzorec „(\u003d A2: A6 * B2: B6)“ sa zobrazí na paneli vzorcov a výsledok sa získa vo všetkých bunkách C2: C6.
Z A D A N I E 2
1) Spustite program EXCEL.
2) Vo svojom vlastnom adresári vytvorte súbor s názvom „lab_2.хls“.
3) Prvý list zošita pomenujte „Lab. Č. 2 (zadávanie vzorcov) “.
4) Do bunky A1 napíš svoje priezvisko.
5) Vytvorte vysvedčenie podľa vzorovej tabuľky. 2. Súčet položiek v každom stĺpci a každom riadku. Vypočítajte priemerné skóre pomocou vzorcov.
Tabuľka 2
Matematika |
Ekonomika |
Počítačová veda |
Priemerné skóre |
|
Ivanov |
5 |
|||
Petrov |
4 |
|||
Sidorov |
3 |
|||
Jakovlev |
4 |
|||
Priemerné skóre |
4 |
6) Spočítajte počet "5" značiek v každom predmete. Vytlačte zoznam študentov s GPA vyšším ako „4“.
7) Vypočítajte y \u003d 2 x 2 + 3 x + 5, kde sa argument x zmení z 0,1 na 1 v krokoch 0,1. Použite absolútne referencie pre konštanty 2, 3, 5 a relatívne referencie pre x.
8) Pre maticu 4´4 vypočítajte jej determinant, jeho inverznú maticu, zarovnajte ju a nájdite transponovanú maticu pomocou tabuľkových vzorcov.
9) Uložte obsah zošita.